
Snowflake
Snowflake is a Software-as-a-Service (SaaS) platform enabling a wide variety of workloads and applications on any cloud, including data warehouses, data lakes, data pipelines, and data sharing as well as business intelligence, data science, and data analytics applications. Snowflake’s architecture is a hybrid of traditional shared-disk database architectures and shared-nothing database architectures. It supports the most common standardized version of SQL: ANSI, including DDL statements to manage database objects such as schemas, tables, columns and indexes. The VARIANT data type lets users store semi-structured file formats including JSON, Avro, ORC and Parquet.
To perform data modeling for Snowflake with Hackolade, you must first download the Snowflake plugin.
Hackolade was specially adapted to support the data modeling of Snowflake, including schemas, tables and views, plus the generation of DDL Create Table syntax. In particular, Hackolade has the unique ability to model complex semi-structured objects stored in columns of the VARIANT data type. The reverse-engineering function, if it detects JSON documents, will sample records and infer the schema to supplement the DDL table definitions. The application closely follows the Snowflake terminology and storage structure.
The data model in the picture below results from the data modeling of the sample weather data available in some regions of the trial sandbox:

Schemas
A schema is a logical grouping of database objects (tables, views, etc.). Each schema belongs to a single database. Together, a database and schema comprise a namespace in Snowflake. When performing any operations on database objects in Snowflake, the namespace is inferred from the current database and schema in use for the session.
Tables
All data in Snowflake is stored in database tables, logically structured as collections of columns and rows, optionally with single-column or multi-column constraints. Snowflake does not use indexes, which is one of the things that makes it scale for arbitrary queries. Instead, Snowflake calculates statistics about columns and records in files that you load, and uses those statistics to figure out what parts of what tables/records to actually load to execute a query.
Hackolade Studio supports the use of dynamic tables in Snowflake, including Iceberg, where you specify the query used to transform the data from one or more base objects or dynamic tables. We also support hybrid tables.
Catalog integration is possible, either the Snowflake Open Catalog, or using an external catalog: Glue, Iceberg files, Delta files, or Iceberg REST.
Unique, Primary, and Foreign Keys, and Not Null
Snowflake supports the following constraint types from the ANSI SQL standard: UNIQUE, PRIMARY, FOREIGN, and NOT NULL.
Note: Snowflake supports defining and maintaining constraints, but does not enforce them, except for NOT NULL constraints, which are always enforced.
Clustering Keys
In general, Snowflake produces well-clustered data in tables; however, over time, the data in some table rows may no longer cluster optimally on desired dimensions. To improve the clustering of the underlying table micro-partitions, you can always manually sort rows on key table columns and re-insert them into the table; however, performing these tasks could be cumbersome and expensive. Instead, Snowflake supports automating these tasks by designating one or more table columns/expressions as a clustering key for the table. A table with a clustering key defined is considered to be clustered.
Data types
Snowflake supports the most basic SQL data types (with some restrictions) for use in columns. Data types are automatically coerced whenever necessary and possible. Snowflake VARCHAR holds unicode characters.
In addition to the standard ANSI SQL data types, Snowflake also supports the semi-structured data types: VARIANT, OBJECT and ARRAY to represent arbitrary data structures which can be used to import and operate on semi-structured data (JSON, Avro, ORC, Parquet, or XML.) Snowflake stores these types internally in an efficient compressed columnar binary representation of the documents for better performance and efficiency.
Currently, Hackolade lets you model JSON structures and data types in VARIANT, plus during reverse-engineering, will detect JSON and infer the schema. Similar support for Avro, ORC and Parquet is foreseen, but not yet available.
Hackolade also supports Snowflake User-Defined Types via its re-usable object definitions.
(Materialized) Views
A view allows the result of a query to be accessed as if it were a table. The query is specified in the CREATE VIEW statement. Views serve a variety of purposes, including combining, segregating, and protecting data.
Hackolade supports Snowflake (materialized) views, via a SELECT of columns of the underlying base table, to present the data of the base table with a different primary key for different access patterns.
When creating a View in Hackolade Studio, you may choose columns to be included by picking them in the list (add column toolbar button, or contextual menu > Add column > Pick from list.) Or you have the flexibility to customize your SQL query by specifying your own JOIN and WHERE clauses. To streamline the process and avoid repeating column names that are already defined in the View's model, you can use the placeholder #8202;${viewColumns}. This placeholder will be automatically replaced with the relevant columns of the View when the script is generated, ensuring you don’t have to type them out manually.
Example of a SELECT Statement
SELECT ${viewColumns}
FROM MySchema.A
INNER JOIN MySchema.B ON A.ColumnA = B.ColumnB
WHERE A.ColumnAA IS NOT NULL;
Functions, Procedures, Sequences, File Formats, and Stages
You can extend the SQL you use in Snowflake by writing user-defined functions (UDFs) and stored procedures that you can call from SQL. When you write a UDF or procedure, you write its logic in one of the supported handler languages, then create it using SQL.
Sequences are used to generate unique numbers across sessions and statements, including concurrent statements. They can be used to generate values for a primary key or any column that requires a unique value.
Snowflake File format is a named database object that can be used to simplify the process of accessing the staged data and streamlines loading data into and unloading data out of database tables. A Snowflake File format encapsulates information of data files, such as file type (CSV, JSON, etc.) and formatting options specific to each type used for bulk loading/unloading.
Stages are locations where data files are stored (staged) for loading and loading data. They are used to move data from one place to another, and the locations for the stages could be internal or external to the Snowflake environment.
In Hackolade Studio, functions, procedures, sequences,file formats, and stages are declared and maintained at the schema level, where you find dedicated tabs in the Properties Pane.
Tags
Tags play a role in sorting and organizing items into distinct categories or groups, facilitating easier navigation through content. They also act as metadata, offering extra information about an item or data. This added context aids in filtering and comprehending the content without needing to review it in full.
In Snowflake, tags are implemented as schema-level objects that can be assigned to another Snowflake object at any level: schema, table, column, or view. A tag can be assigned a string value while assigning the tag to an object. Snowflake stores the tag and its string value as a key-value pair. The tag must be unique for a given schema, and the tag value is always a string.
According to the Snowflake specification, a tag must be first CREATEd at the schema level, before it can be SET with a value for a given schema, table, column, or view. In Hackolade Studio for Snowflake, this declaration of a new tag is done in the Tags tab at the schema level:
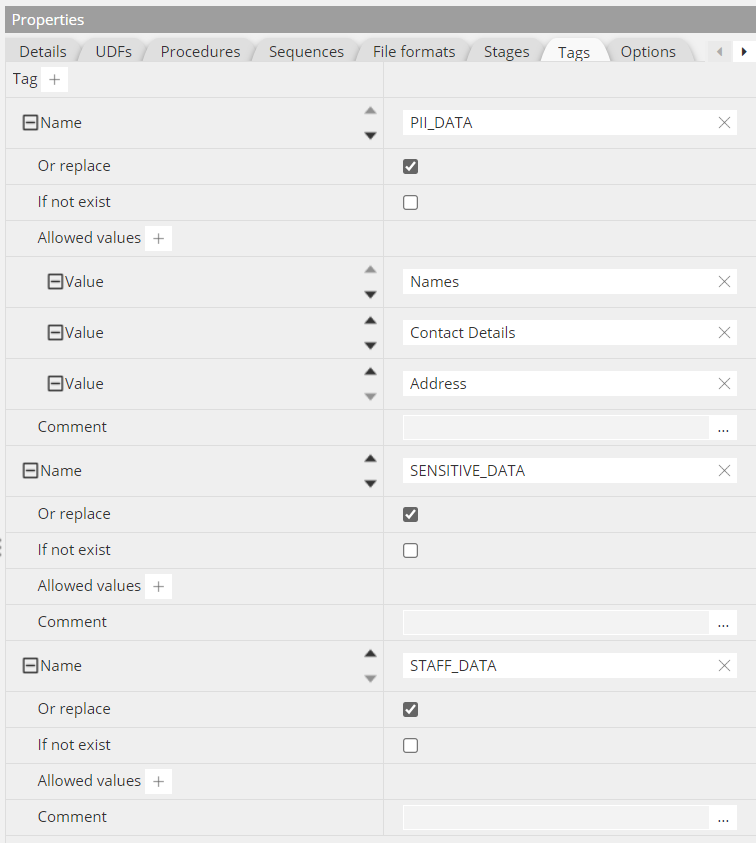
These entries result in the automatic creation of the corresponding lines in the DDL script:

These tags can now be referenced at any level (schema, table, column, and/or view), for example for a table:
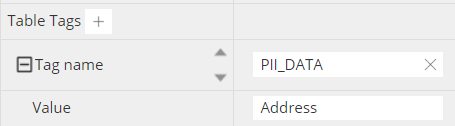
which results in the corresponding DDL syntax being automatically generated:

Note that, tags being set at the schema level require an ALTER SCHEMA command as the tag can only be SET after it has been CREATEd on an existing schema:
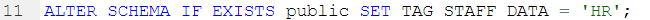
You may find parts of this article useful to understand how to use tags in Snowflake, knowing of course that Hackolade Studio handles the generation of the required DDL syntax, for example:
Forward-Engineering
Hackolade dynamically generates the DDL script to create schemas, tables, columns and their data types, for the structure created with the application.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.

If you store JSON within VARIANT columns, Hackolade allows for the schema design of those documents. However, the corresponding JSON structure is not forward-engineered in the DDL script, but is useful for developers, analysts and designers.
Reverse-Engineering
A Snowflake account can be hosted on any of the following cloud platforms: Amazon Web Services, Google Cloud Platform, or Microsoft Azure. Each platform provides one or more regions where the account is provisioned. Details on how to connect Hackolade to Snowflake can be found on this page.
The Hackolade process for reverse-engineering of Snowflake databases includes the execution of DDL DESCRIBE statements to discover schemas, tables, columns and their data types. If JSON is detected in VARIANT columns, Hackolade performs statistical sampling of records followed by probabilistic inference of the JSON document schema.
For more information on Snowflake in general, please consult the website. See also this excellent hands-on lab guide.