Storage Formats & IDLs







Apache Avro Schema
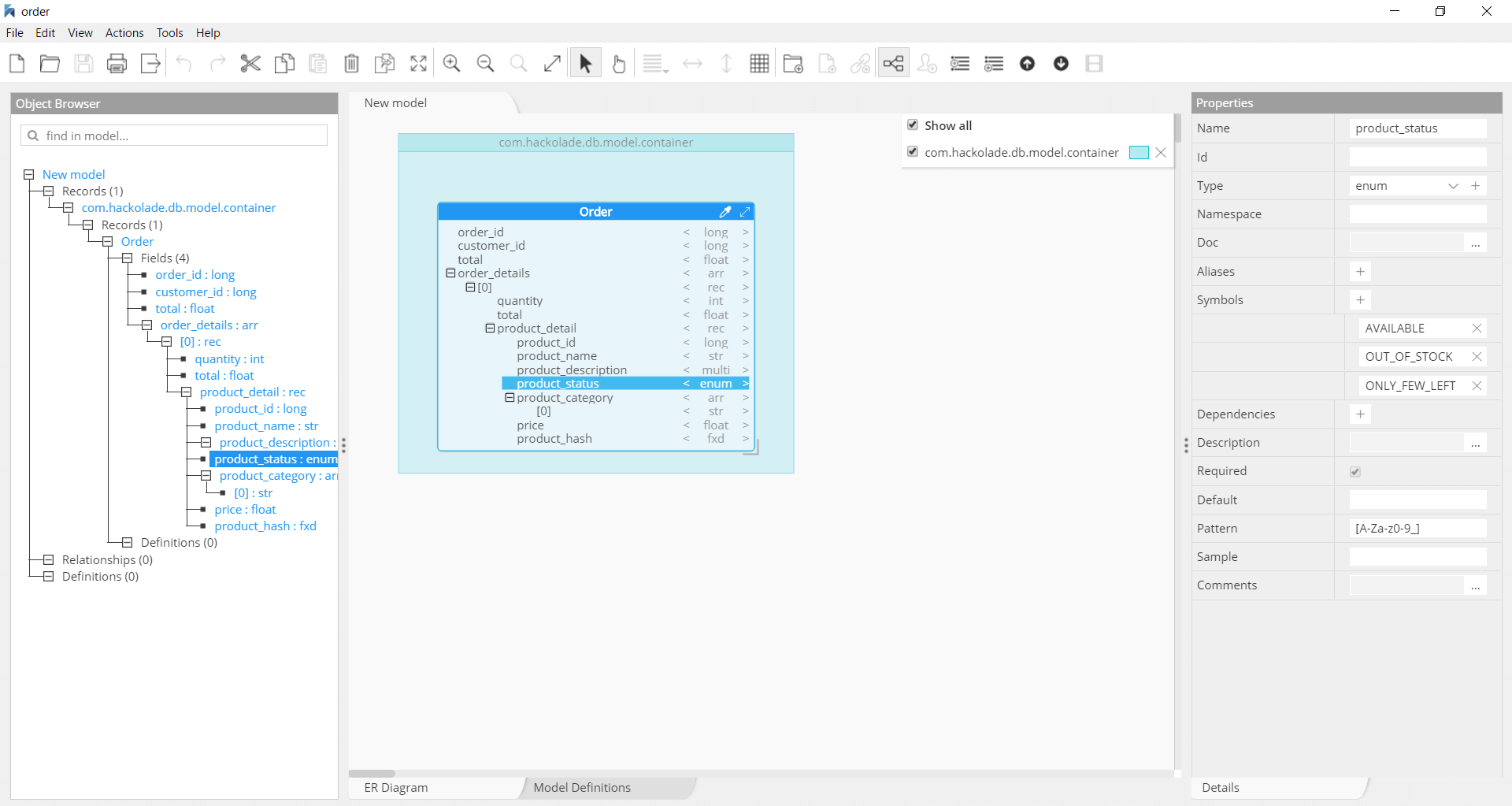
Serialize data in Hadoop and stream data with Kafka
Apache Avro is a language-neutral data serialization system, developed by Doug Cutting, the father of Hadoop. Avro is a preferred tool to serialize data in Hadoop. It is also the best choice as file format for data streaming with Kafka. Avro serializes the data which has a built-in schema. Avro serializes the data into a compact binary format, which can be deserialized by any application. Avro schemas defined in JSON, facilitate implementation in the languages that already have JSON libraries. Avro creates a self-describing file named Avro Data File, in which it stores data along with its schema in the metadata section.
Hackolade was specially adapted to support the data modeling of Avro schemas. It closely follows the Avro terminology, and dynamically generates Avro schema for the structure created with a few mouse clicks. Hackolade easily imports the schema from .avsc or .avro files to represent the corresponding Entity Relationship Diagram and schema structure.
JSON Schema
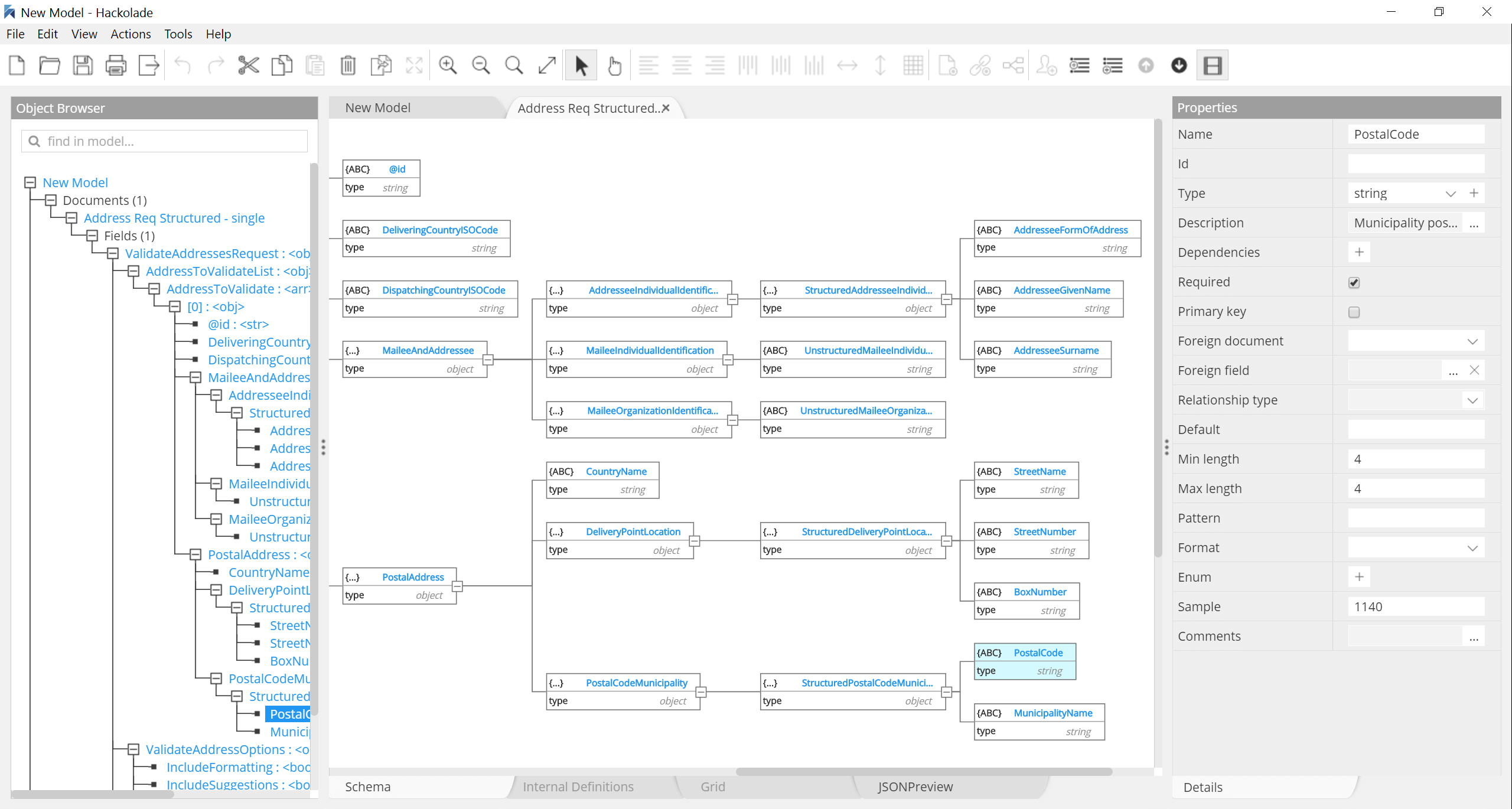
JSON is increasingly dominating the application development world
Hackolade is a visual editor of JSON Schema. It supports all the advanced features, including choices and polymorphism, patterns fields, and conditional subschemas. With Hackolade, it is easy to visually create a JSON Schema from scratch, and without prior knowledge of the syntax. You can also easily derive JSON Schema from JSON document files. All recent specifications are supported: draft-04, draft-06, draft-07, 2019-09, and 2020-12.
Apache Parquet Schema
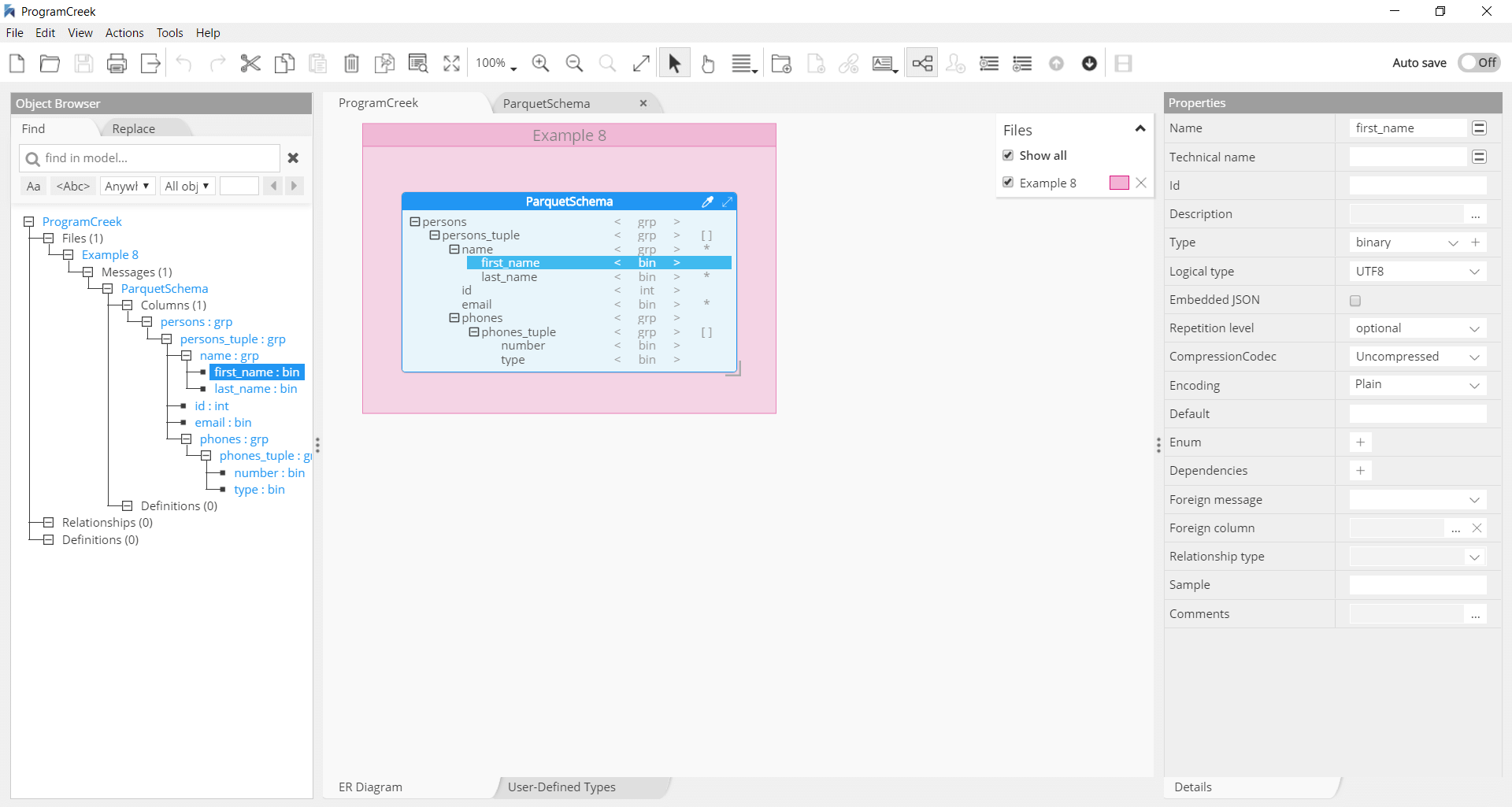
Visual schema design to serialize data in columnar format
Apache Parquet is a binary file format that stores data in a columnar fashion for compressed, efficient columnar data representation in the Hadoop ecosystem, and in cloud-based analytics. Hackolade is a visual editor for Parquet schema for non-programmers, and specifically adapted to support the schema design of Parquet files. It supports the Parquet structure, data types, logical types, encodings, compression codecs, and all other standard metadata. Hackolade dynamically generates parquet schema as the model is created via the application. It also lets you perform reverse-engineering of files on the local system, shared directories, AWS S3 buckets, Azure Blob Storage, or Google Cloud Storage.
Protocol Buffers a.k.a Protobuf

Language-neutral, platform-neutral, extensible mechanism for serializing structured data
You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
Hackolade is a visual editor for Protobuf schema for non-programmers. It was specially adapted to support the design of Protobuf schemas. It closely follows the Protocol Buffers terminology, and dynamically generates gRPC/Protobuf for the structure created with a few mouse clicks. Hackolade easily imports the schema from .proto files to represent the corresponding Entity Relationship Diagram and schema structure.
YAML files
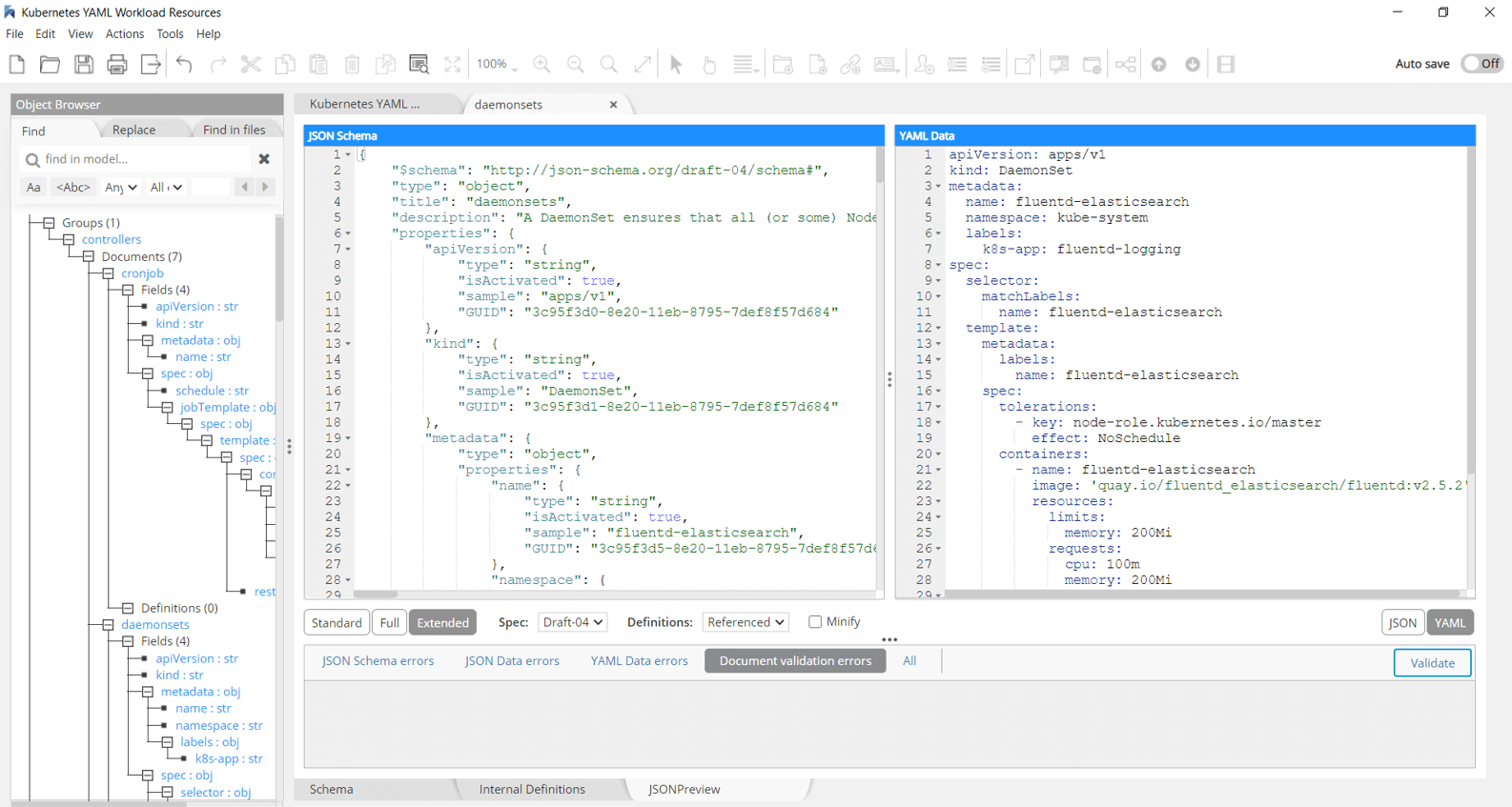
Use JSON Schema to validate YAML documents
Reliance upon syntactic whitespace can be frustrating, particularly in the context of infrastructure-as-code and Kubernetes deployments,
While YAML has advanced features that cannot be directly mapped to JSON, most YAML files use features that can be validated by JSON Schema. JSON Schema is the most portable and broadly supported choice for YAML validation. Hackolade now support the reverse-engineering of YAML files and generation of sample data in YAML, plus forward- and reverse-engineering of YAML Schema.