NoSQL Column-Oriented Databases

DataStax


Apache Cassandra and DataStax
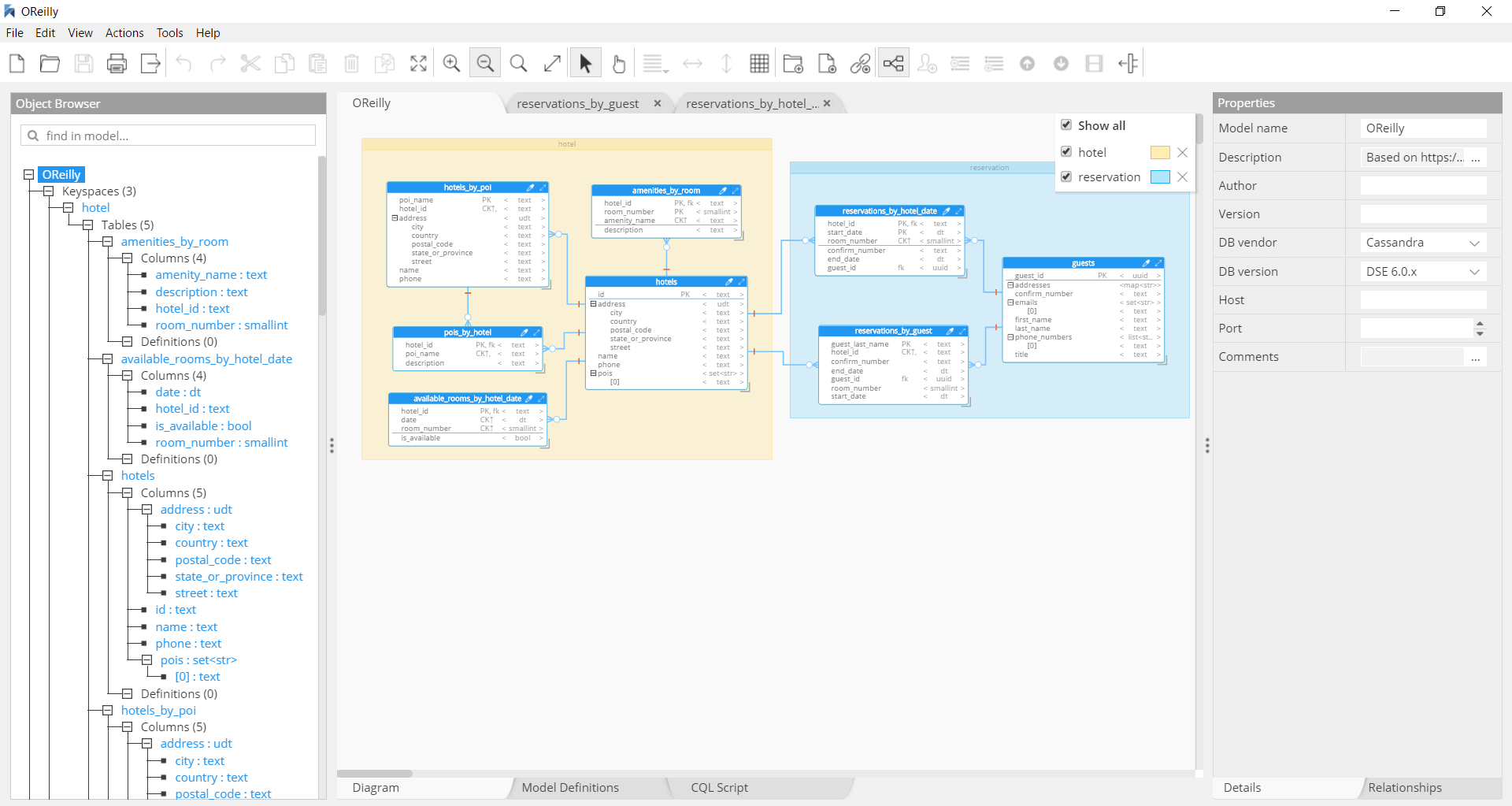
Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure
The Apache Cassandra NoSQL database is the right choice when you need scalability and high availability without compromising performance, and with no single point failure.
Hackolade was specially adapted to support the data modeling of Cassandra, including User-Defined Types and the concepts of Partitioning and Clustering keys. It lets users define, document, and display Chebotko physical diagrams. The application closely follows the Cassandra terminology, data types, and Chebotko notation.
The reverse-engineering function includes the table definitions, indexes, user-defined types and functions, but also the inference of the schema for JSON structures if detected in text or blob.
Apache HBase
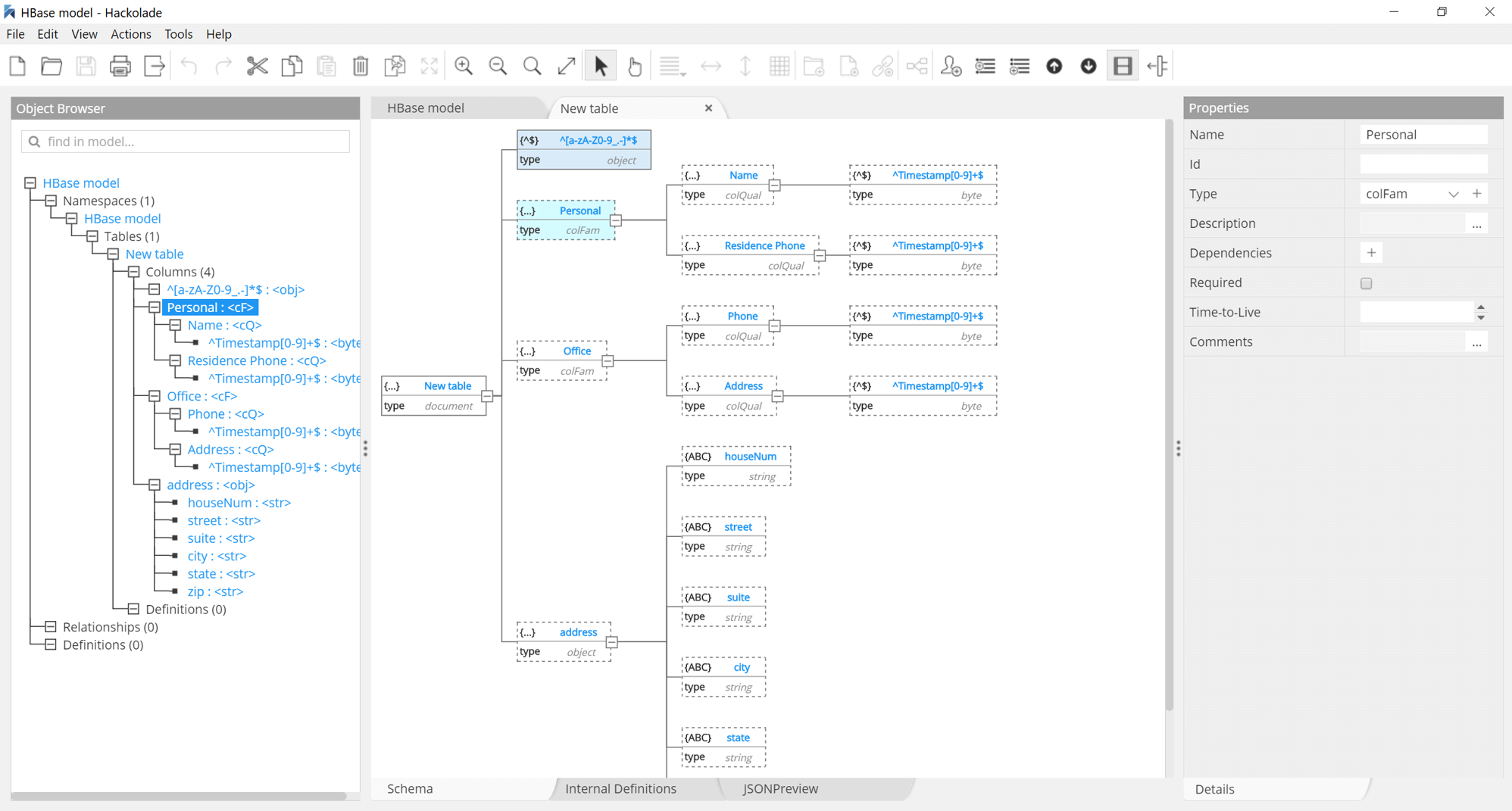
When you need random, realtime read/write access to your Big Data
Apache HBase is an open-source, distributed, versioned, non-relational (NoSQL) database modeled after Google's Bigtable. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware.
Hackolade was specially adapted to support the data modeling of HBase, whether you store your data in column families or as a JSON object. With our reverse-engineering function, you can easily discover, document, and enrich the structure of your column families and qualifiers, plus infer the structure of JSON documents you store in HBase.
ScyllaDB
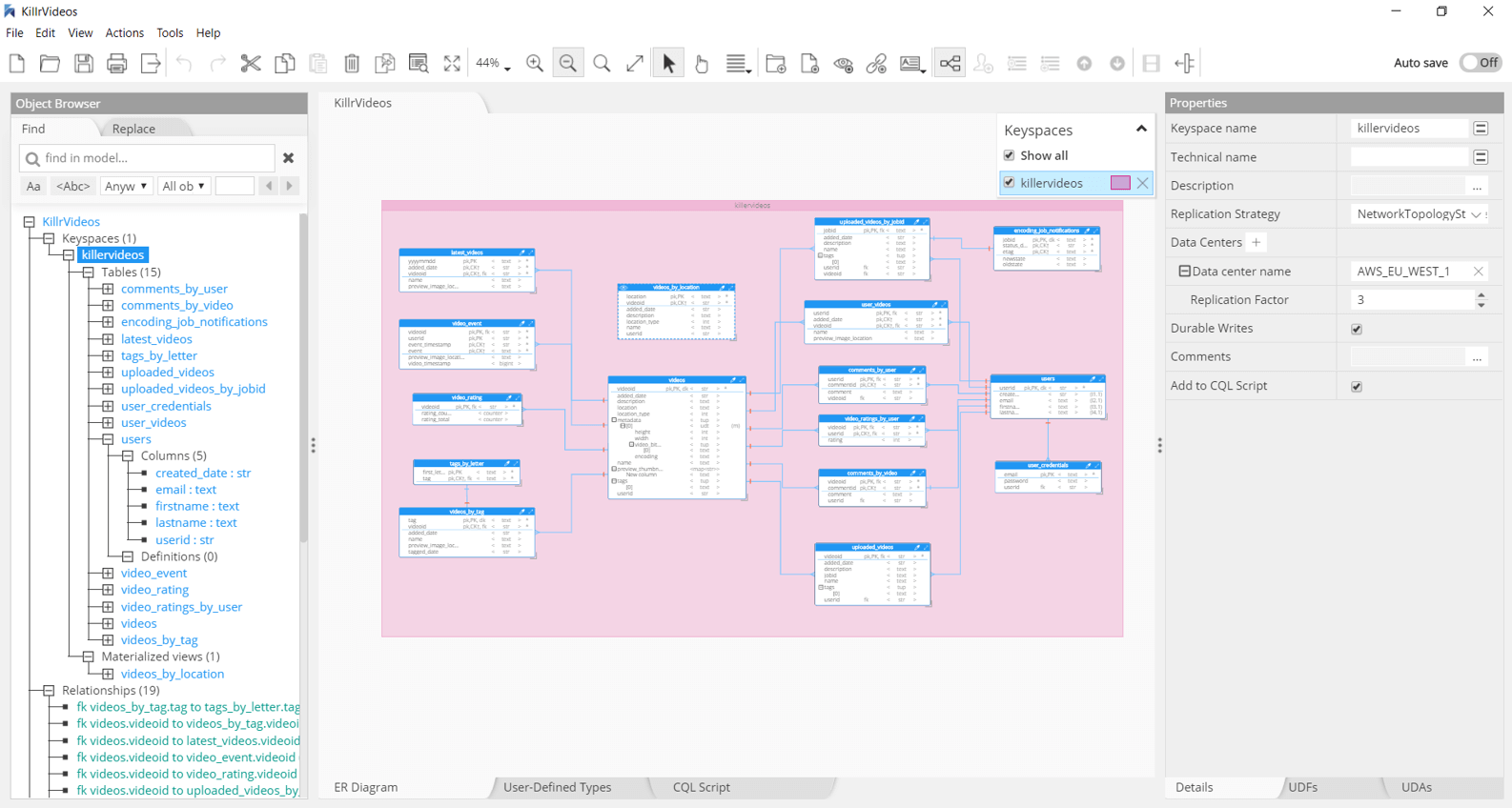
Lightning fast throughput and ultra-low latency
ScyllaDB is an open-source distributed NoSQL column-oriented data store, designed to be compatible with Apache Cassandra. It supports the same CQL query language but is written in C++ instead of Java to increase raw performance and leverage modern multi-code servers self-tuning.
Hackolade was specially adapted to support the data modeling of ScyllaDB, including User-Defined Types and the concepts of Partitioning and Clustering keys. It lets users define, document, and display Chebotko physical diagrams. The application closely follows the ScyllaDB terminology, data types, and Chebotko notation.
The reverse-engineering function includes the table definitions, indexes, user-defined types and functions, but also the inference of the schema for JSON structures if detected in text or blob.