Big Data Analytics
on Databricks




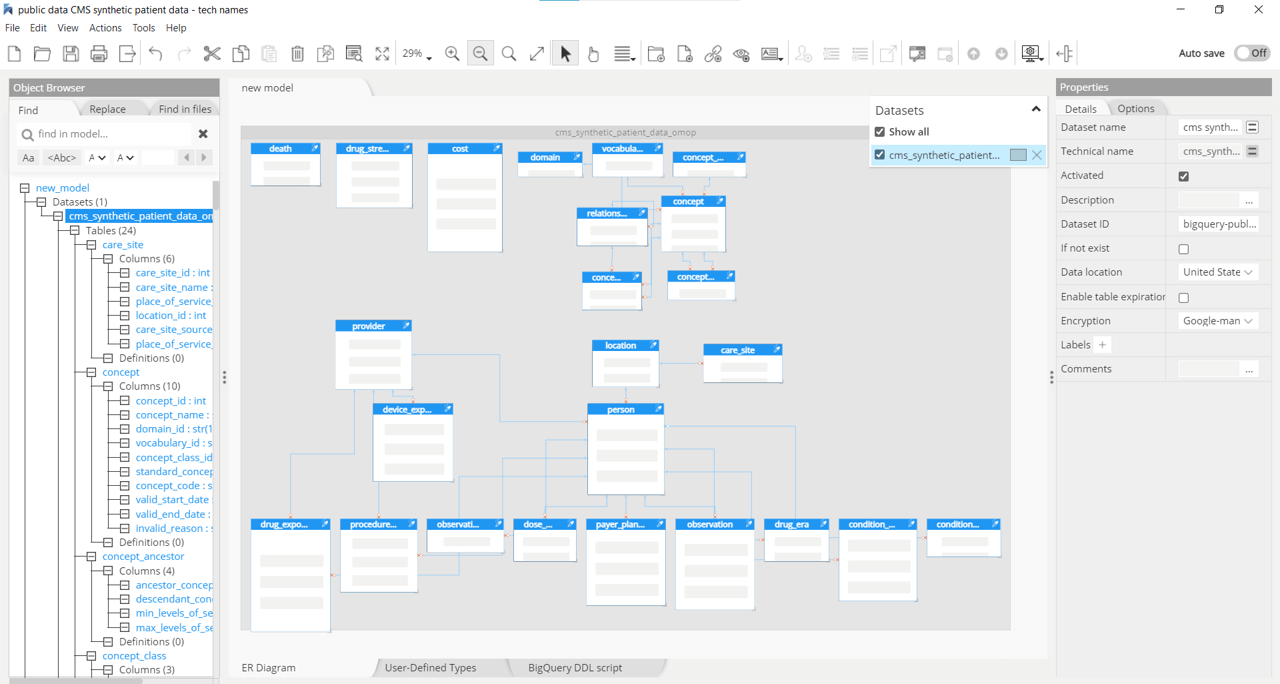
Google BigQuery
Run analytics over vast amounts of data in near real time
BigQuery uses managed columnar storage, massively parallel execution, and automatic performance optimizations. With familiar ANSI-compliant SQL, BigQuery manages the technical aspects of storing structured data, including compression, encryption, replication, performance tuning, and scaling.
Hackolade was specially adapted to support the data modeling of BigQuery, including datasets, tables and views, plus the generation of DDL Create Table syntax, in Standard SQL or in JSON Schema. Hackolade natively supports the ability to represent nested complex data types: STRUCT (record) and ARRAY.
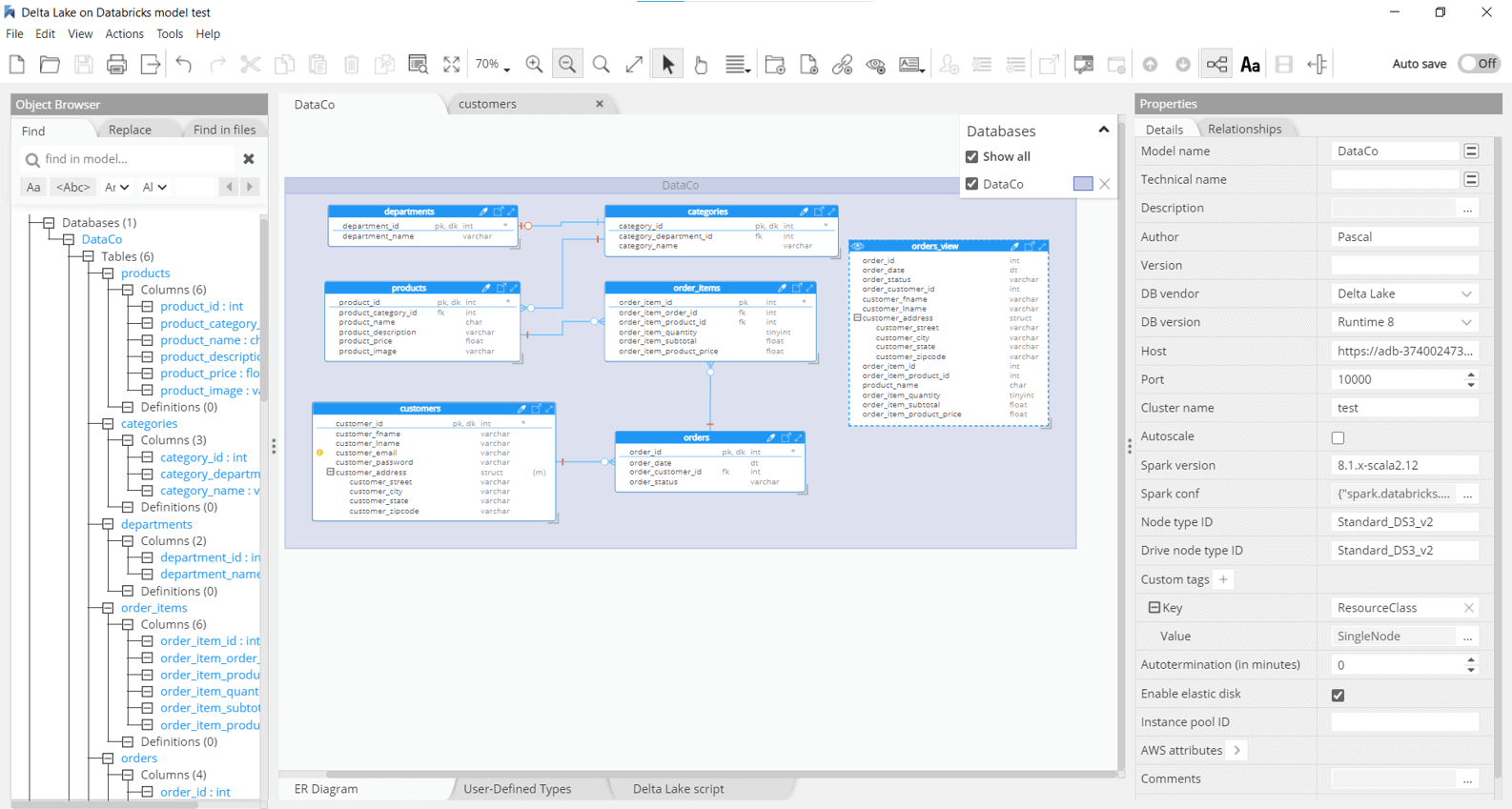
Delta Lake on DataBricks
Deliver a reliable single source-of-truth for all data
With support for ACID transactions and schema enforcement, Delta Lake provides the reliability that traditional data lakes lack. This enables to scale reliable data insights throughout the organization and run analytics and other data projects directly on data lakes. The Databricks platform runs on Azure, AWS, and Google cloud.
Hackolade was specially adapted to support the data modeling of Delta Lake, including the Databricks storage structure of clusters, databases, tables and views. It leverages Hive primitive and complex data types, plus user-defined types. And combines it all with the usual capabilities of forward-engineering of HiveQL scripts, reverse-engineering, documentation generation, model comparison, command-line interface integration with CI/CD pipelines, etc...The application closely follows the Delta Lake terminology.
Microsoft Fabric
Fabric is a unified data platform that integrates various Microsoft data tools and services, primarily aimed at data engineers, analysts, and developers. It provides an end-to-end solution for data management, analytics, and machine learning. The platform is designed to simplify working with large datasets, enabling organizations to manage, analyze, and visualize data seamlessly.
Apache Hive
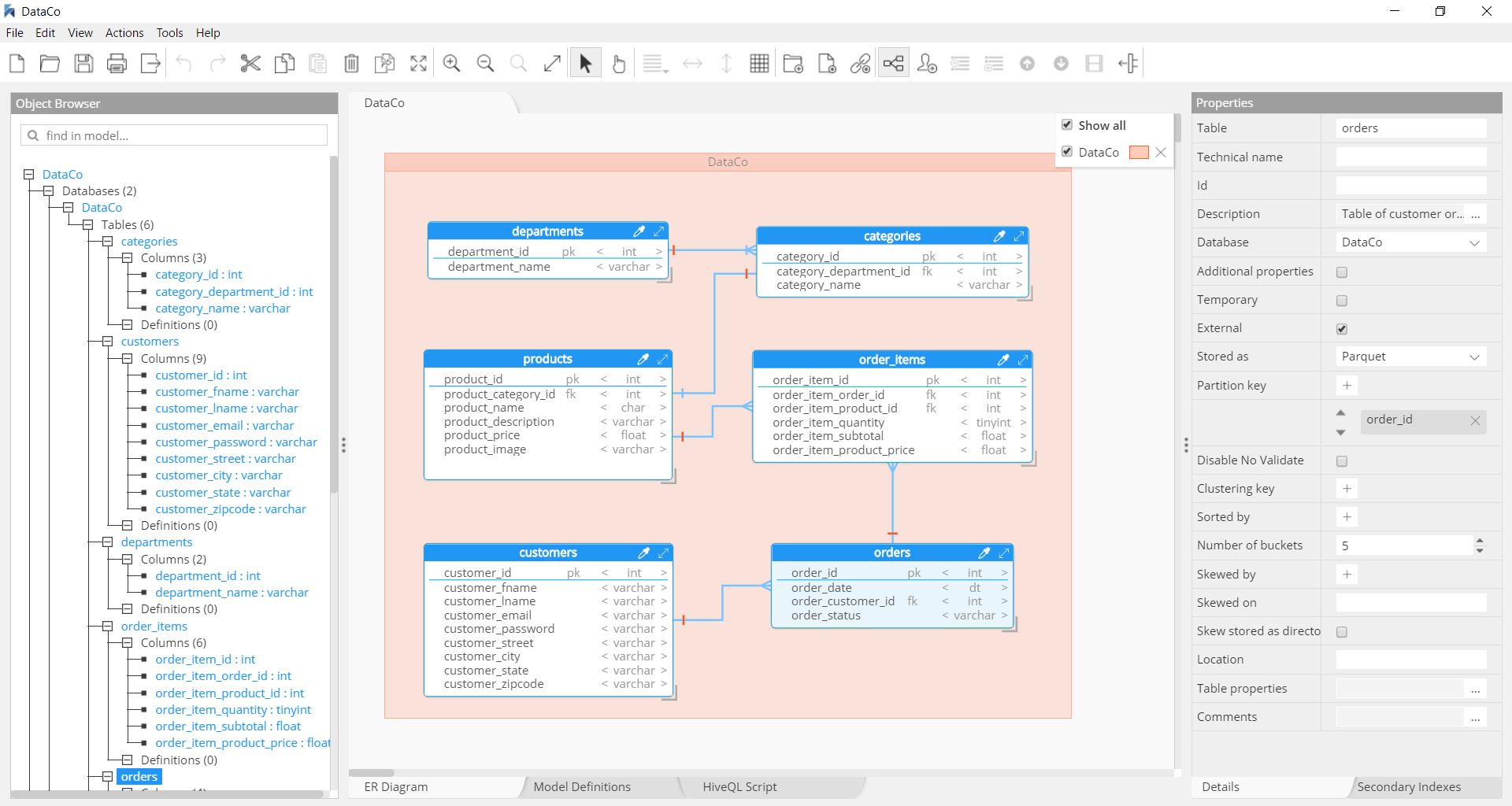
Hadoop Hive Data Modeling
Apache Hive is an open source data warehouse system built on top of Hadoop for querying and analyzing large datasets stored in Hadoop files, using HiveQL (HQL), which is similar to SQL. HiveQL automatically translates SQL-like queries into MapReduce jobs. This provides a means for attaching the structure to data stored in HDFS.
Hackolade was specially adapted to support the data modeling of Hive, including Managed and External tables and their metadata, partitioning, primitive and complex datatypes. It dynamically forward-engineers HQL Create Table scripts, as the structure is built in the application. You may also reverse-engineer Hive instances to display the corresponding ERD and enrich the model. The application closely follows the Hive, terminology and storage structure.
Amazon Redshift
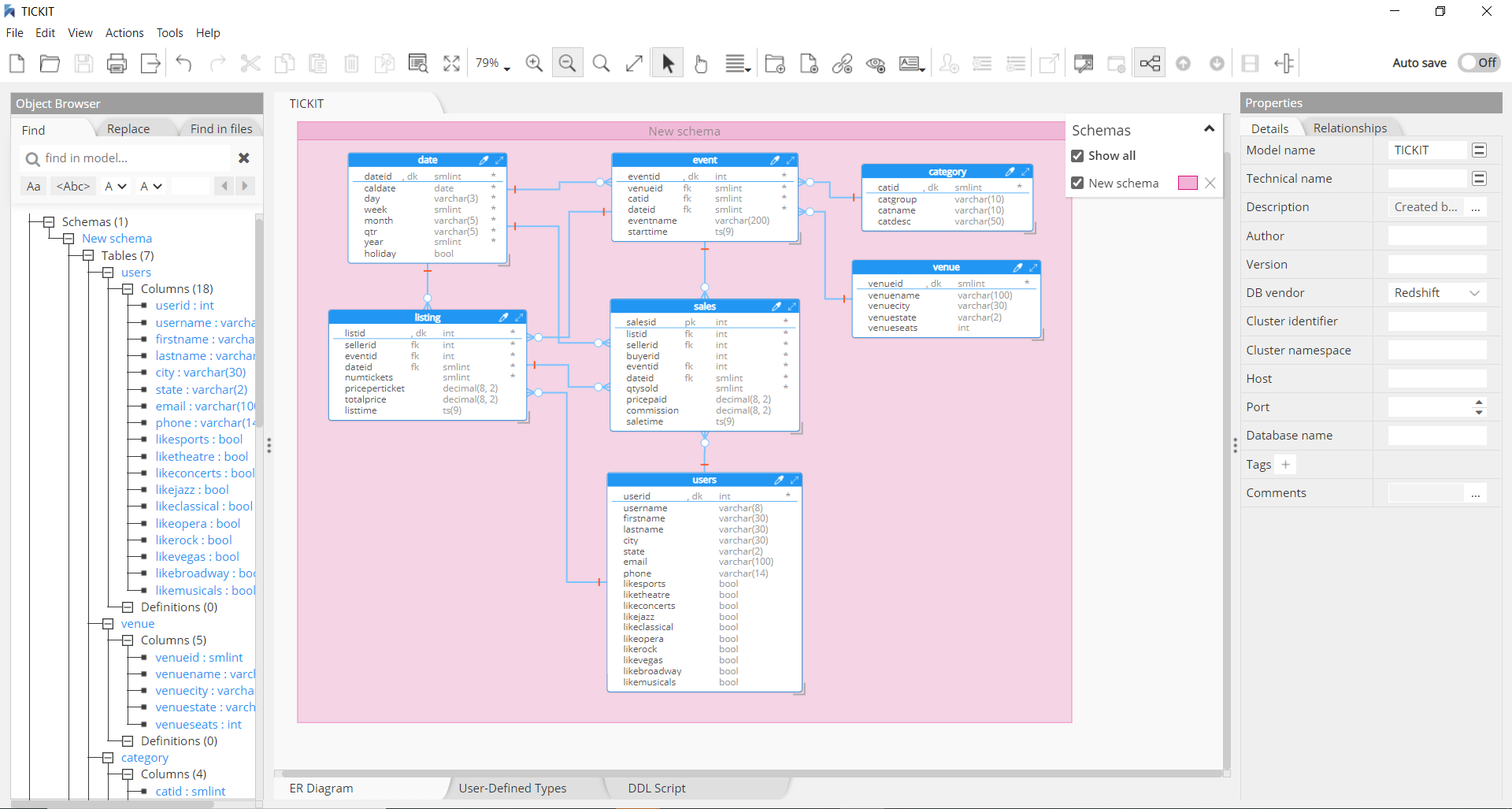
Amazon Redshift is a data warehouse product built on top of technology from massive parallel processing (MPP) to handle complex queries against large data sets.
Hackolade was specially adapted to support the data modeling of Redshift, including schemas, tables and views, plus the generation of DDL Create Table syntax as the model is created via the application. In particular, Hackolade has the unique ability to model complex semi-structured objects stored in columns of the SUPER data type. The reverse-engineering function, if it detects JSON documents, will sample records and infer the schema to supplement the DDL table definitions.
Snowflake
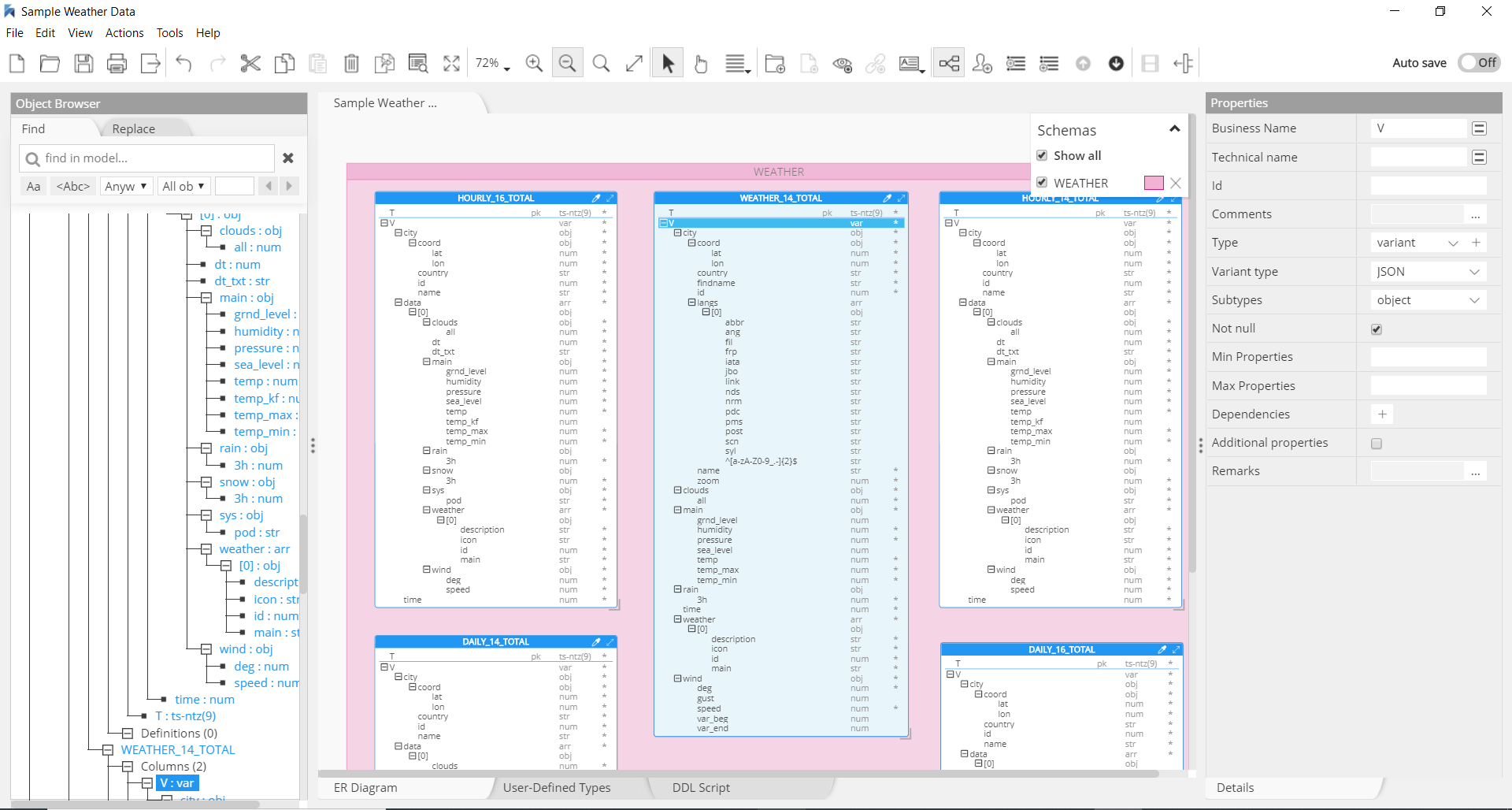
Cloud-based data warehousing
Snowflake’s architecture is a hybrid of traditional shared-disk database architectures and shared-nothing database architectures. It supports the most common standardized version of SQL: ANSI.
Hackolade was specially adapted to support the data modeling of Snowflake, including schemas, tables and views, indexes and constraints, plus the generation of DDL Create Table syntax as the model is created via the application. In particular, Hackolade has the unique ability to model complex semi-structured objects stored in columns of the VARIANT data type. The reverse-engineering function, if it detects JSON documents, will sample records and infer the schema to supplement the DDL table definitions.
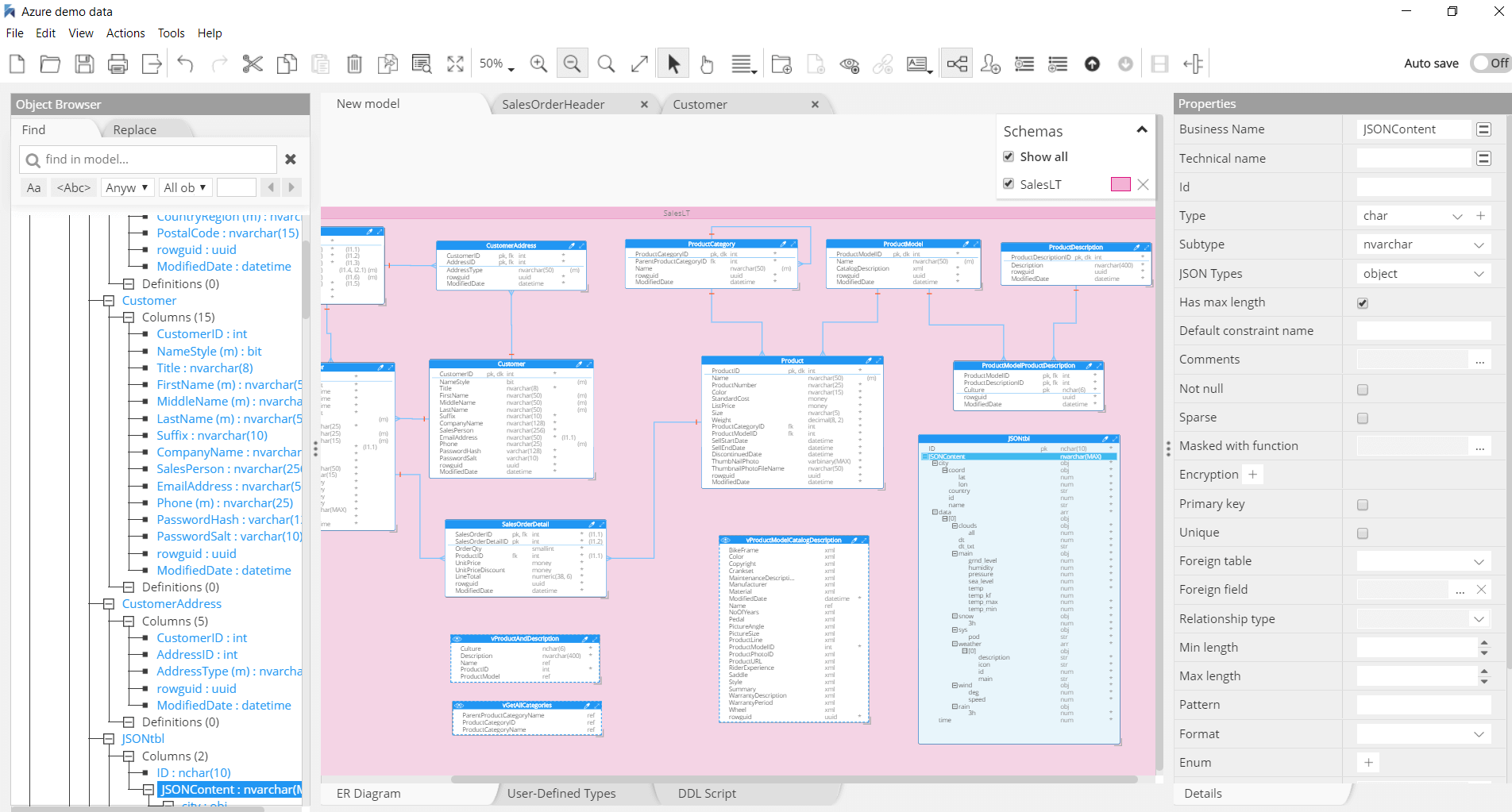
Azure Synapse Analytics
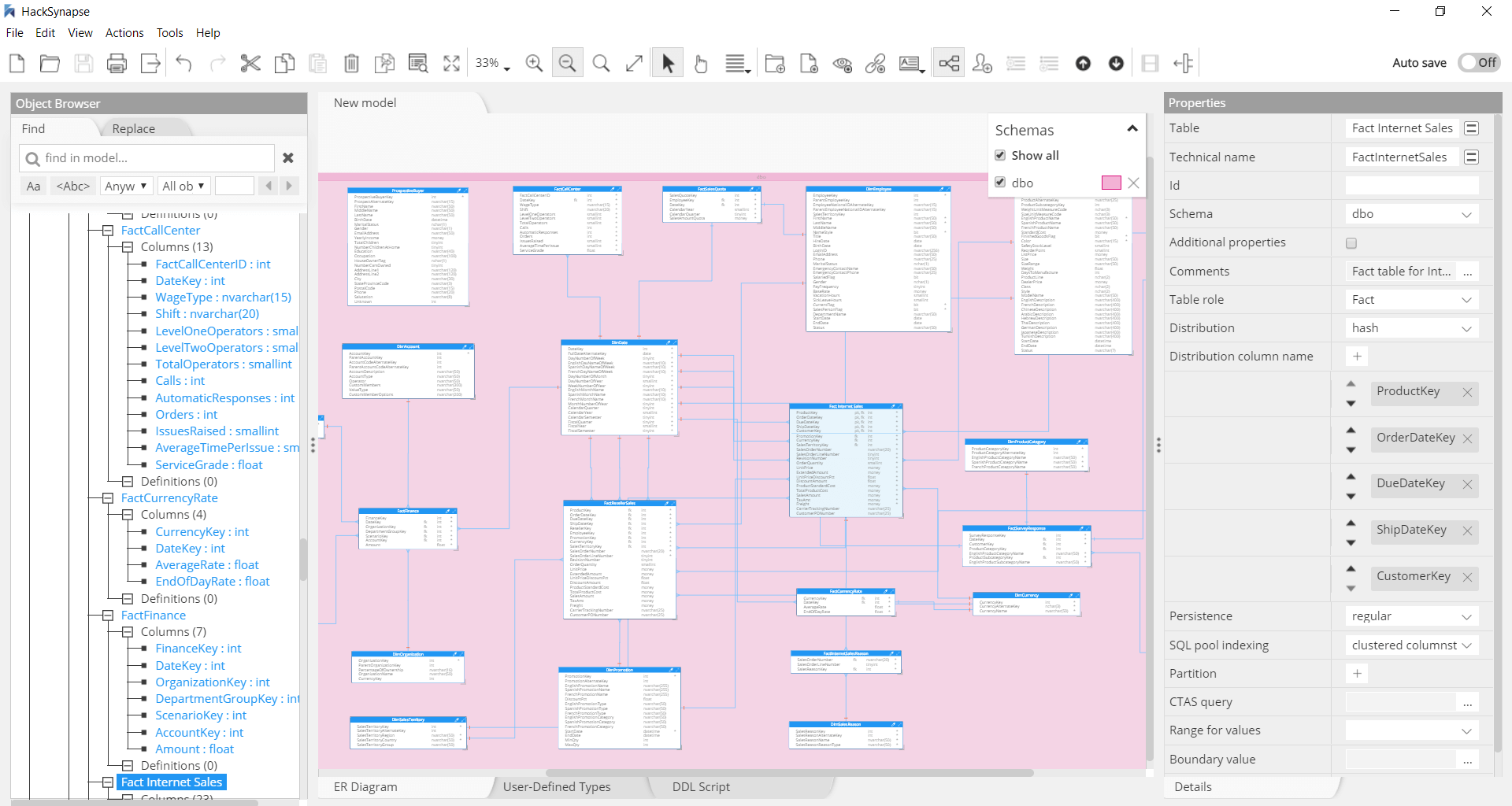
Data modeling for serverless analytics
Azure Synapse Analytics and Parallel Data Warehouse are a limitless analytics service that brings together enterprise data warehousing and Big Data analytics. It uses either serverless or provisioned resources with a unified experience to ingest, prepare, manage, and serve data for immediate BI and machine learning needs.
Hackolade has the unique ability to model complex semi-structured objects stored in columns of the (N)VARCHAR(MAX) data type. The reverse-engineering function, if it detects JSON documents, will sample records and infer the schema to supplement the DDL table definitions. Hackolade was specially adapted to support the data modeling of Azure Synapse Analytics and Parallel Data Warehouse, including schemas, tables and views, plus the generation of DDL Create Table syntax.
Teradata Vantage
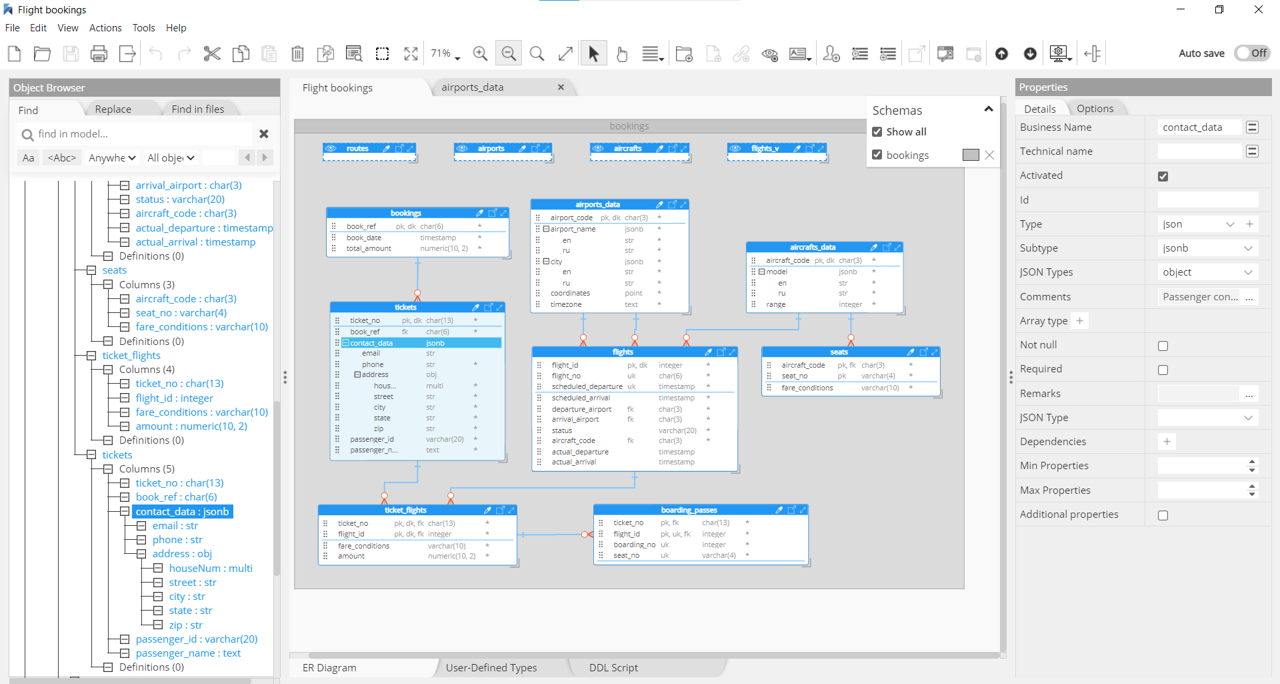
Big data analytics and semi-structured data in the cloud
Fabric is a unified data platform that integrates various Microsoft data tools and services, primarily aimed at data engineers, analysts, and developers. It provides an end-to-end solution for data management, analytics, and machine learning. The platform is designed to simplify working with large datasets, enabling organizations to manage, analyze, and visualize data seamlessly.
Hackolade supports Fabric through its SQL Server/Azure SQL and Synapse plugins, including reverse-engineering, documentation generation, model comparison, command-line interface integration with CI/CD pipelines, etc...