Use cases
from scratch
an existing instance
API generation
and denormalize
regulatory compliance
Start a model from scratch

Dynamically generate forward-engineering scripts and documentation with just a few mouse clicks
When starting a new project, the database model is at the core of your application. With Hackolade, you can get started in no time! With just a few mouse clicks, you generate sample documents, database scripts, and HTML or PDF documentation. In an Agile approach, you can engage in a meaningful dialog between analysts, designers, architects, developers and DBAs, playing what-if scenarios. It reduces development costs and increases your chances to deliver an evolving application that responds to your customer’s needs.
Reverse-engineer an existing instance

Further enrich the model with relationships, descriptions and constraints, then generate HTML, Markdown or PDF documentation
If you have a running database instance, you may want to document the data model, share it, and discuss its evolution with application stakeholders who would prefer not looking at code. In just a few mouse clicks, you connect to the instance, select the tables and collections you want, and your base model is created. We will draw an ERD from the DDL, or for NoSQL databases, our machine-based data discovery and cataloging process includes statistical sampling of documents, followed by a probabilistic inference of the schema.
You can print pretty ER diagrams and hierarchical schema views of your collection schemas, or distribute HTML, Markdown, or PDF documentation so users easily understand the structure of the data. You may also enrich the model with descriptions, constraints, and comments.
Model-driven API generation

Generate APIs based on database ERD models
Hackolade introduces the ability to directly generate an OpenAPI (or Swagger) model and documentation from any Hackolade model target. This feature will help make your APIs more consistent than those produced by hand, while easily exposing resources for underlying data sources. API maintenance will be greatly facilitated, and Total Cost of Ownership reduced.
Furthermore, it is possible to automatically create resources (request and responses) for each entity of the source data model, based on a user-defined template. The template can be defined in different ways: a Hackolade model file for Swagger or OpenAPI, or an actual Swagger/OpenAPI documentation file in either JSON or YAML.
Suggest denormalization of SQL schema
Based on a relational model, Hackolade can easily reference, embed, and denormalize
Migration from RDBMS SQL to NoSQL requires a mind shift, and Hacklolade can help in the migration of a schema from a normalized relational model to a model combining embedding and referencing. You generate a Data Definition Language (DDL) file from Oracle, Microsoft SQL Server, MySQL, PostgreSQL, Hadoop Hive, or Sybase. You then reverse-engineer it with Hackolade and generate a relational model of the schema.
Then select an least 2 tables to which denormalization should be applied, choose 2-way referencing or the type of embedding (sub-document in child, array in parent, or both) and the number of cascading levels that should be applied.
You now have a denormalized schema, along with its documentation and forward-engineering scripts.
Data governance and regulatory compliance
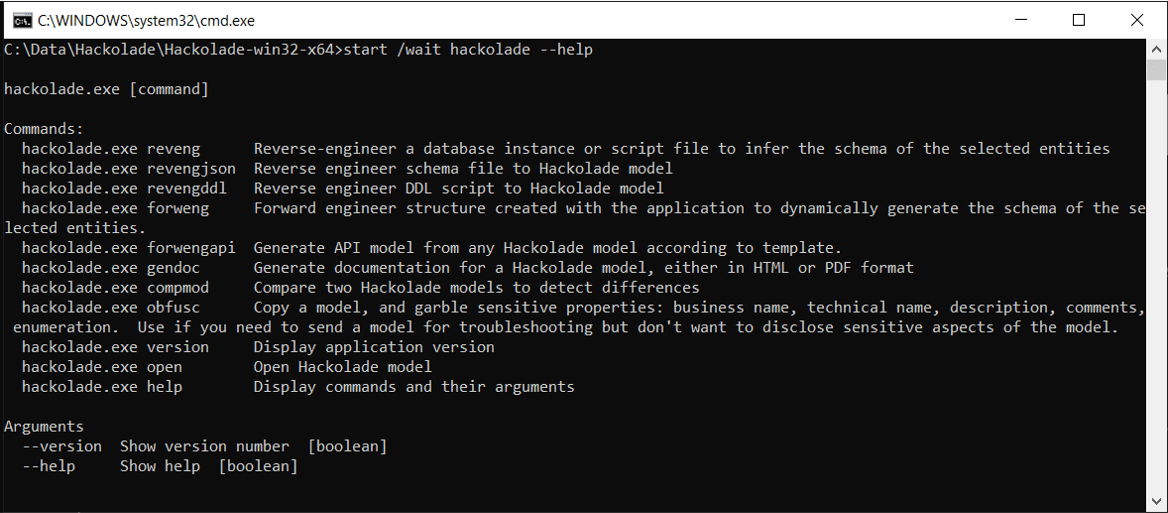
Automated data discovery in an agile world
With its Command Line Interface (CLI), Hackolade truly supports an agile development approach leveraging the flexibility of NoSQL dynamic schemas. Some Hackolade customers use this capability nightly in a batch process to identify attributes and structures that may have appeared in the data since the previous run.
During a nightly batch of the reverse-engineering function, a much larger dataset can be queried as a basis for document sampling, hence making schema inference more precise.
Such capability can be useful in a data governance context to properly document the semantics and publish a thorough data dictionary for end users. It can also be used in the context of compliance with privacy laws to make sure that the company does not store data that it is not supposed to store.
Generate fake but realistic data
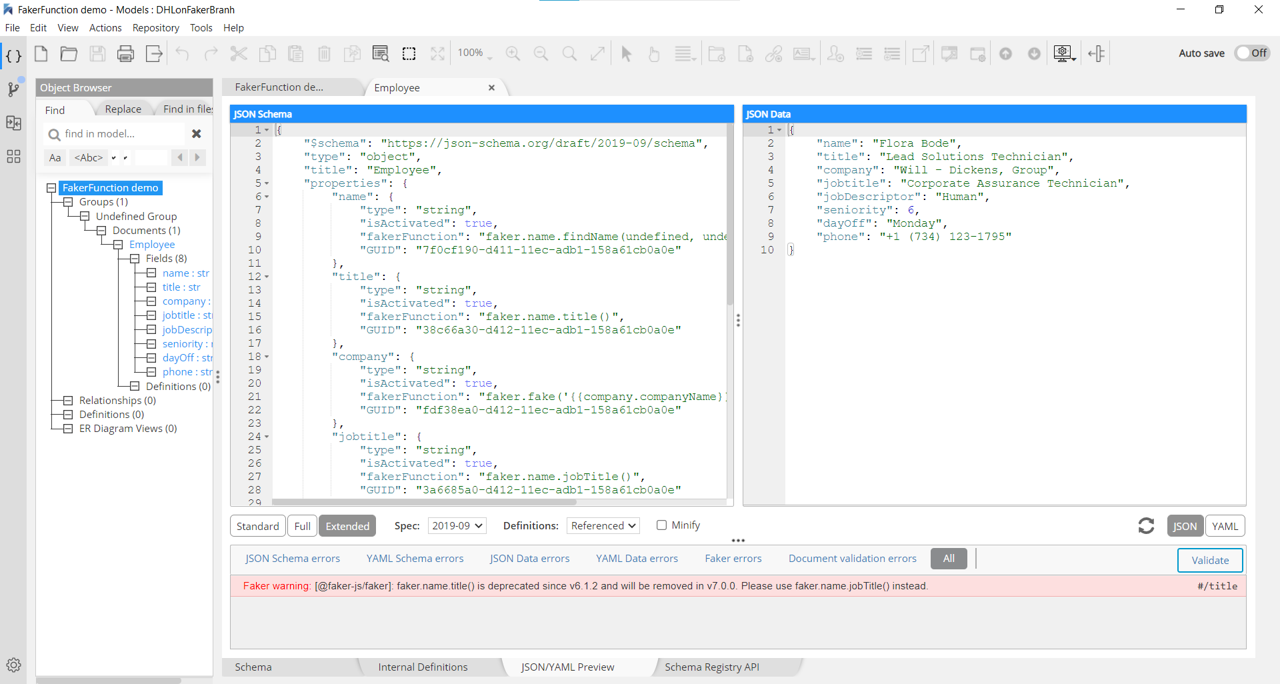
For system development, testing, and demos
Using mock data avoids using real identities, full names, real credit card numbers or Social Security numbers, etc. Using "Lorem ipsum" strings and random numbers is not a realistic enough to be meaningful. Alternatively, one could use cloned production data, except that it generally does not exist for new applications, plus you would still have to mask or substitute sensitive data to avoid disclosing any personally identifiable information.
Moreover, manually generating fake data takes time and slows down the testing process, particularly if large volumes are required.
The solution is to use Hackolade Studio to generate mock data, i.e. fake but realistic data. With Hackolade, you can generate first names and last names that look real but are not, and the same for company names, product names and descriptions, street addresses, phone numbers, credit card numbers, commit messages, IP addresses, UUIDs, image names, URLs, etc..