Videos
Vision & Overview
Hackolade helps to reconcile Business and IT through a shared understanding of the context and meaning of data. Technology-agnostic data models generate physical schemas for different targets. Co-located code and data models provide a single source-of-truth for business and technical stakeholders.
Polyglot Data Modeling
With Hackolade Studio, users can define structures once in a technology-agnostic polyglot data model, complete with denormalization and complex data types, then represent these structures in a variety of physical data models respecting the specific aspects of each target technology.
Metadata-as-Code
Co-locate data models and their schema artifacts with application code, so they can follow the lifecycle of application changes. Provides a single source-of-truth for business and technical stakeholders as the data model in the Git repo is the source of the technical schemas used by applications, databases, and APIs at the same time as it is the source for the business-facing data dictionaries. This architecture contributes to the shared understanding of the context and meaning of data by all the stakeholders.
Domain-Driven Data Modeling
ackling complexity at the heart of data. With Domain-Driven Data Modeling (DDDM) the main principles are:
- focus on your core ("domain and sub-domains")
- break down complex problems into smaller ones ("bounded context")
- use data modeling as a communication tool ("ubiquitous language")
- keep together what belongs together ("aggregates")
- reach a shared understanding between business and tech ("collaboration of domain experts and developers")
- iterate and evolve ("continuous refinement")
Hackolade Studio Quick Tour
This video provides a tour of the application, and a review of the user interface
Create your first data model with Hackolade Studio
Creation of a data model from scratch to forward-engineer the schema or script to an instance, or to an API, Excel, and data dictionaries. Also creation of a data model from reverse-engineering from a variety of sources, including a database instance, JSON files or JSON Schema, DDLs, XSDs, Excel, etc.
Hackolade Studio Workgroup Edition overview
Native integration with Git repositories to provide state-of-the-art collaboration, versioning, branching, conflict resolution, peer review workflows, change tracking and traceability. It allows to co-locate data models and schemas with application code, and further integrate with DevOps CI/CD pipelines as part of our vision for Metadata-as-Code.
Download and install Hackolade Studio
In this video, you can see how to get going with Hackolade Studio in barely 2 minutes.
Reverse-engineering of a MongoDB instance
The application performs a statistical sampling of each collection, followed by a probabilistic inference of the fields in the documents sampled. Finally, it transforms it into a Hackolade schema. You're now ready to enrich the model with comments and constraints. You can declare and document implicit relationships. In the end, you get a visual representation that lets you easily query the database and perform a better analysis of the data. More info

Create a model from scratch and perform forward-engineering
Create a model from scratch, then generate a MongoDB createCollection script with validation, a Mongoose schema, or a detailed documentation in PDF. More info
SQL DDL reverse-engineering and denormalization assistance
In this video, we reverse-engineer a DDL for the Northwind relational database, then we denormalize it in order to leverage the power of NoSQL document DBs and JSON. More info
Re-usable object definitions
In this video session, we explain in detail the handy feature of Hackolade to facilitate the work of data modelers: it provides the ability to create - once - object definitions that can be re-used in multiple places. More info Online documentation
Naming Conventions
In this video session, we explain in detail a new Hackolade feature that lets you maintain both a ‘business name’ and a ‘technical name’ for model objects. This feature can be useful if the database target has attribute length limitations for example, or if you wish to store abbreviated field names in the database, while keeping detailed names for documentation purposes. More info Online documentation
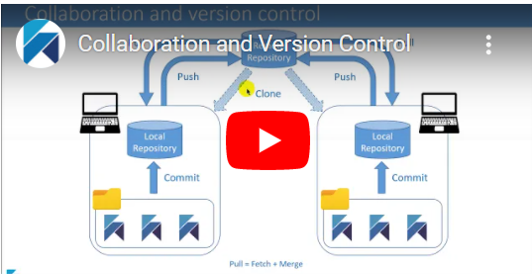
Collaboration and Version Control
In this video session, we explain in detail how to leverage the capabilities of Git, to easily collaborate and manage changes in your Hackolade models. We will only go over very basic processes without covering Git advanced features such as forks, branches, pull requests, etc… which would be outside the scope of this video. More info Online documentation
Schema-centric API design with Swagger and OpenAPI
In this video session, we explain how to visually design a REST API using Swagger or OpenAPI, using Hackolade's schema-centric approach. Online documentation

Data Modeling is Dead... Long Live Schema Design!
DataStax Accelerate conference: When it comes to managing data for modern, agile environments, is data modeling a roadblock? Or is it in fact one of the keys to achieving agility? If traditional data modeling will no longer support what businesses need today, what are the alternatives? Related blogpost

NoSQL Data Modeling in Practice
CoMoNoS 2020: 1st Workshop on Conceptual Modeling for NoSQL Data Stores Co-located with the ER 2020 conference.

Increase API Quality and Consistency with Model-Driven API Generation
In this demo session, you’ll see how NoSQL schema designs based on access patterns can be converted into full API specifications with a few mouse clicks, to serve as a basis for API-driven development. A customizable API template lets users control the output configuration and create APIs that customers and developers will love. View slides

Data modeling and schema design for Cosmos DB
Facilitate migration from RDBMS to Cosmos DB through denormalization to leverage the scalability, flexibility, and easy evolution of schemas for Cosmos DB.
In this session, we will demonstrate how data modeling helps harness the power of Cosmos DB, resulting in reduced development time, increased application quality, and lower execution risks across the enterprise.

Collibra Data Dictionary Integration
Collibra and Hackolade have teamed up to develop an integration of their solutions so that schema designs performed in Hackolade Studio and visual Entity-Relationship diagrams can be easily deployed to Collibra. Data Citizens add business context to create a unified view of all data assets, no matter the data storage or data exchange technology. Learn more

Migration from SQL to MongoDB with Studio3T
Studio 3T makes it possible to easily migrate either selected tables or an entire SQL database into MongoDB Atlas using the SQL Migration tool. And now, with Hackolade integration, both work in concert to enable easy, trackable, scheduled migrations from legacy SQL systems to modern data platforms like MongoDB Atlas.
Twitch: how to use Hackolade for data modeling with Amazon DocumentDB
Hosts Karthik Vijayraghavan and Cody Allen for the 14th episode of "Amazon DocumentDB Insider Hour". In this episode, Pascal Desmarets announces support for Amazon DocumentDB and explains how Hackolade can help with document modeling for Amazon DocumentDB workloads.
Migrating SQL Schemas for ScyllaDB: Data Modeling Best Practices
To maximize the benefits of ScyllaDB, you must adapt the structure of your data. Data modeling for ScyllaDB should be query-driven based on your access patterns– a very different approach than normalization for SQL tables. In this session, you will learn how tools can help you migrate your existing SQL structures to accelerate your digital transformation and application modernization. View slides
In’s and Out’s of Polyglot Data Modeling
Polyglot persistence lets enterprises store different kinds of data in different data stores, depending on how data is being used. The trend complements the evolution towards microservices, and introduces a whole range of new questions about consistency of the data and consistency of the data structure. The same data is described over and over again, in different languages, different formats, and different data types. As a result, things get lost and out-of-sync, leading to data quality challenges...

Schema design with JSON
Tens of thousands of organizations, from startups to the largest companies and government agencies, are looking to automatically generate JSON Schema easily. Using the latest NoSQL Data Modeling solutions, organizations can move faster and build applications with more confidence and speed than ever before.

Understanding NoSQL Document Database Schema Design
NoSQL databases are designed so that you don’t have to create a schema to build a database. But it’s a common mistake to think that NoSQL databases don’t require any sort of schema design. Bottom line you still need a blueprint.
How-To: Reusable definitions
The purpose of reusable definitions is to increase productivity/convenience and consistency to achieve higher data quality and governance. It is a handy feature of Hackolade Studio to facilitate the work of data modelers: it provides the ability to create and maintain object definitions that can be re-used in multiple places.
How-To: User-defined custom properties
Hackolade Studio is shipped with standard properties displayed in the Properties Pane. These properties are specific to each object in a data model. They are specific for each target technology, and can even be different for each data type.
Many users want to define their own properties, for example to track PII or GDPR characteristics, or to tie with metadata management and governance. Some power users create hooks to be leveraged in DevOps CI/CD pipelines or in code generation routines.
How-To: Pre-populate new entities using snippets
To avoid the repetitive task of adding the same set of attributes to new entities as you create a model, you may leverage reusable definitions. But there's another option to pre-populate new entities with the same structure, through JSON configuration, using the concept of snippets.
How-To: Composite key constraints
Composite keys are declared at the entity level, in the Properties Pane tab "Composite keys":. In general, you may give a name to the composite key constraint.
How-To Command-Line Interface Playlist (5 videos)
With its Command Line Interface (CLI), Hackolade supports an agile development approach leveraging the flexibility of NoSQL dynamic schemas. Some customers use this capability nightly in a batch process to identify attributes and structures that may have appeared in the data since the last run.
How-To: CLI reverse-engineering (1 of 5)
Reverse-engineer a database instance to fetch or infer the schema of the selected collections/tables
How-To: CLI model comparison (2 of 5)
Compare two Hackolade models to detect differences, and optionally merge them.
How-To: CLI generation of DDL script (3 of 5)
Forward-engineer structure created with the application to dynamically generate the schema DDL of the selected entities. Or forward-engineer JSON Schema or a sample JSON data document.
How-To: CLI documentation generation (4 of 5)
Generate documentation for a Hackolade model, in HTML, Markdown, or PDF format.
How-To: CLI orchestration with batch script (5 of 5)
The orchestration of the commands and arguments is typically scripted, then triggered by an event or a schedule. The sequence of steps depends on whether development has the upper hand or governance.
Polyglot Data Modeling example
Define structures once in a technology-agnostic polyglot data model, complete with denormalization and complex data types, then represent these structures in a variety of physical data models respecting the specific aspects of each target technology.
Watch this example with MongoDB, Avro for Kafka, and OpenAPI

Hackolade Studio Tutorial Playlist (13 videos)
You don't need extensive training to create a simple data model. But to be a power user, you need to be aware of all the bells and whistles provided to handle real-life situations.
Hackolade Tutorial - Part 1: What is a data model?
First in a series of tutorials for Hackolade Studio. A data model is an abstract representation of how elements of data are organized, how they relate to each other, and how how they relate to real-world concepts...
Hackolade Tutorial - Part 2: Overview of JSON and JSON schema
JSON stands for JavaScript Object Notation. It is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate.
Hackolade Tutorial - Part 3: Query driven data modeling based on access patterns
Data modeling for relational databases is performed according to the rules of normalization, so larger tables are divided into smaller ones linked together with relationships. The purpose is to eliminate redundant or duplicate data. But NoSQL databases are completely different. They require a mindshift in schema design in order to leverage their capabilities, as well as a data modeling tool built specially for this new breed of state-of-the art technology.
Hackolade Tutorial - Part 4: Create your first data model
By the end of this tutorial, you will master different ways to enter information in Hackolade Studio, as well as different ways to visualize structures you've created.
Hackolade Tutorial - Part 5: Add nested objects and arrays
By the end of this tutorial, you will master the creation of more complex data structures.
Hackolade Tutorial - Part 6: Add choice, conditional, pattern fields
By the end of this tutorial, you will master the creation of other types of JSON Schema attributes: choices, conditionals, and pattern fields.
Hackolade Tutorial - Part 7: Add relationships
By the end of this tutorial, you will master how to add relationships to your entity-relationship diagram.
Hackolade Tutorial - Part 8: Import or reverse-engineer
By the end of this tutorial, importing data structures and reverse-engineering of existing instances will have no secrets for you.
Hackolade Tutorial - Part 9: Export or forward-engineer
By the end of this tutorial, you will master exporting or forward-engineering of schemas and order artifacts for your data models.
Hackolade Tutorial - Part 10: Generate documentation and pictures
By the end of this tutorial, you will have learned how to generate documentation and pictures for your data model.
Hackolade Tutorial - Part 11 - Create a model for graph databases
By the end of this tutorial, you will have learned how to generate documentation and pictures for your data model.
Hackolade Tutorial - Part 12: Create a REST API model
By the end of this tutorial, you will master how to create a model for REST APIs using Swagger or OpenAPI specification.
Hackolade Tutorial - Part 13: Leverage a Polyglot data model
By the end of this tutorial, you will master how to perform data modeling for polyglot storage and transmission, using our Polyglot Data Modeling capabilities.
How-to: Create a model for Avro schema
Apache Avro is a language-neutral data serialization system, developed by Doug Cutting, the father of Hadoop. Avro is a preferred tool to serialize data in Hadoop. It is also the best choice as file format for data streaming with Kafka. Avro serializes the data which has a built-in schema. Avro serializes the data into a compact binary format, which can be deserialized by any application. Avro schemas defined in JSON, facilitate implementation in the languages that already have JSON libraries. Avro creates a self-describing file named Avro Data File, in which it stores data along with its schema in the metadata section.
How-To: Oracle 23c Duality Views
Duality Views expose data stored in relational tables as JSON documents. The documents are materialized -- generated on demand, not stored as such. Duality views are organized both relationally and hierarchically. They combine the advantages of using JSON documents with the advantages of the relational model, while avoiding the limitations of each.
How-To: Compare and merge
An organization may create several different versions through the lifecycle of a model. That may be because of the natural evolution of the application in a design-first process, or just to keep up with changes being applied to the database instance. In any case, it is often required to compare different versions of a model to understand the differences, and optionally to merge these differences and create a new reference model.
How-To: Denormalization
Ease migration from SQL with denormalization suggestions. Hackolade Studio helps with the migration from SQL. You can now reverse-engineer a Data Definition Language (DDL) file from Oracle into a Hackolade model. Then you can apply denormalization functions for embedding and referencing data, and truly leverage the power and benefits of nested objects in JSON and MongoDB or other targets.
How-To: ER Diagram Views
Ease migration from SQL with denormalization suggestions. Hackolade Studio helps with the migration from SQL. You can now reverse-engineer a Data Definition Language (DDL) file from Oracle into a Hackolade model. Then you can apply denormalization functions for embedding and referencing data, and truly leverage the power and benefits of nested objects in JSON and MongoDB or other targets.
How-To: Generate synthetic mock data
Using fake data can be useful during system development, testing, and demos, mainly because it avoids using real identities, full names, real credit card numbers or Social Security numbers, etc. while using "Lorem ipsum" strings and random numbers is not a realistic enough to be meaningful. Alternatively, one could use cloned production data, except that it generally does not exist for new applications, plus you would still have to mask or substitute sensitive data to avoid disclosing any personally identifiable information.
How-To: Export-Import with Excel template
Exchanging data with Excel provides the ability to export a data model, or parts of it, to Microsoft Excel so properties could be easily edited in a tabular format, to be re-imported back into the application. It facilitates productive bulk actions for the maintenance of properties. It also allows creation of a new model - or additions to an existing model - by team members that might not have access to the application.
How-To: Infer PKs and FKs
There can be several reasons why you don't originally have Primary Keys and/or Foreign Keys in your model:
- you have a data model loaded from a source that did not provide them;
- you reverse-engineered from a Big Data Analytics platform that don't support these constraints;
- you decided not to enforce PK and/or FK constraints for performance reasons
This feature identifies candidate PKs and PKs to be added to your model. The algorithm works on the metadata of the entities and attributes without looking at the actual data.
How-To: Naming Conventions
Hackolade Studio includes the ability to maintain both a ‘business name’ and a ‘technical name’ for objects (containers, entities, and attributes.) To facilitate the maintenance of these 2 names, it is possible to keep them synchronized and transformed based on a set of user-driven parameters, and optionally based on a conversion file maintained outside of the application. Name conversion can go both directions: Business-to-Technical, or Technical-to-Business. Furthermore, when performing reverse-engineering, it is assumed that the database instance contains technical names, to be transformed in business names.
How-To: Verify Data Model
Verify the consistency and quality of data models according to a glossary of class and prime terms, and to target-specific attribute rules such as precision/scale for numeric, and length for string data types.
How-To: Docker-based automation
Install the Hackolade Studio CLI on a server, and trigger it to run concurrent multi-threaded sessions in a Docker container, as part of that environment. As part of your CI/CD pipeline, you can trigger data modeling automations and have it perform things like creation of artifacts, forward- and reverse-engineering, model comparisons, documentation generation, ...

Hackolade Studio Workgroup Edition Tutorial Playlist (7 videos)
Hackolade Studio has native integration with Git repositories to provide state-of-the-art collaboration, versioning, branching, conflict resolution, peer review workflows, change tracking and traceability. Mostly, it allows to co-locate data models and schemas with application code, and further integrate with DevOps CI/CD pipelines as part of our vision for Metadata-as-Code.
Workgroup collaboration and versioning
Hackolade Studio has native integration with Git repositories to provide state-of-the-art collaboration, versioning, branching, conflict resolution, peer review workflows, change tracking and traceability. Mostly, it allows to co-locate data models and schemas with application code, and further integrate with DevOps CI/CD pipelines as part of our vision for Metadata-as-Code.
Co-located application code and data models provide the single source-of-truth for business and technical stakeholders.
Workgroup Scenario 1: cosmetic changes
We make a small change to a data model, that does not create a conflict, and it automatically gets merged
{kind=link}
Workgroup Scenario 2: non-conflicting model changes
We make a small change to a data model, but that change DOES NOT require manual intervention to resolve the conflict outside of the normal Git workflow
{kind=link}
Workgroup Scenario 3: conflicting model changes
We make a small change to a data model that requires a manual intervention in the Git workflow to resolve it
{kind=link}
Workgroup Scenario 4a: branch-based changes
We make a small change to a data model that requires a manual intervention in the Git workflow to resolve it
{kind=link}
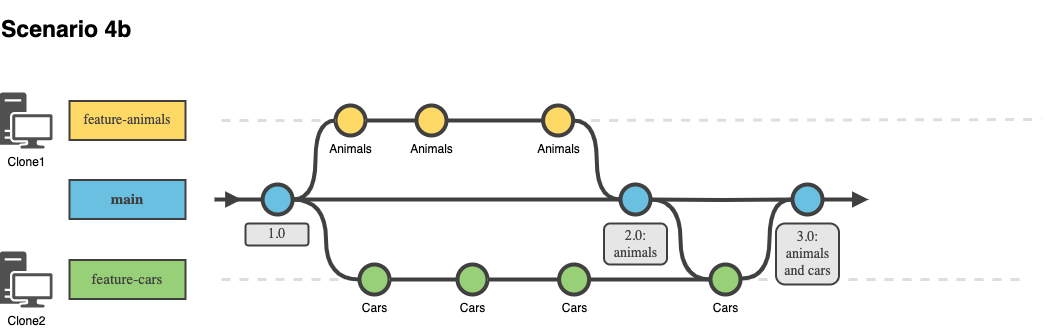
Workgroup Scenario 4b: feature branch changes
We illustrate how you can have two feature branches (feature-cars and feature-animals) that are added to the model, and that are merged together into the main branch.
{kind=link}
Workgroup: Working with Forks
With the fork & pull strategy, contributors create their own (remote) copy of the original repository and push changes to that copy, which is referred to as a fork. Once a contribution is ready, it can be submitted through a pull request: the contributor basically requests the maintainer(s) of the original repository to pull into that repository the work that has been prepared in a fork. Note that nothing prevents multiple contributors from working together in the same fork prior to submitting their changes to the original repository.
The main advantage of the fork & pull strategy is that the contributors do not need to be explicitly granted push access rights to the original repository. That's why that strategy is typically used for large-scale open source projects where most contributors are not known by the maintainers of the repository.
Another advantage of the fork & pull strategy is that it prevents the original repository from being polluted with branches that are created and then abandoned but never deleted by their author.
JSON Relational Duality: Data Modeling with Hackolade
JSON Relational Duality is a marquee feature of Oracle Database 23ai. It combines the benefits of JSON (all information in one document, simple access without joins, schema-flexibility) with the benefits of the relational model (no data duplication, referential integrity, use-case flexibility). One major aspect of JSON Relational Duality is its ability for proper data modeling. In this session we explain the concepts of JSON Relational Duality and why it is capable of solving complex and changing requirements, often found in enterprises where data is long lives and applications change over time.
We also showcase how the Hackolade Studio tool is best used to not only visually plan application collections but also generate JSON Relational Duality views with GUIs.
The Benefits of Domain-Driven Data Modeling
Data Modeling, Is it Dead? This a fundamental question, and we have certainly noticed the following viewpoints about Data Modelling:
• We don't see the value of Data Modeling
• It is hard to convince the Organisation to invest in a Data Modelling Practice / Capability.
• We don't need a Data Model for Agile Development
• NoSQL databases don't require Data Models
Let's restore a balance between a code-first approach which results in poor data quality and unproductive rework, and too much data modeling which gets in the way of getting things done.