Data Modeling Features
Reverse-Engineering
documentation
Core data modeling capabilities
Support for conceptual, logical and physical modeling
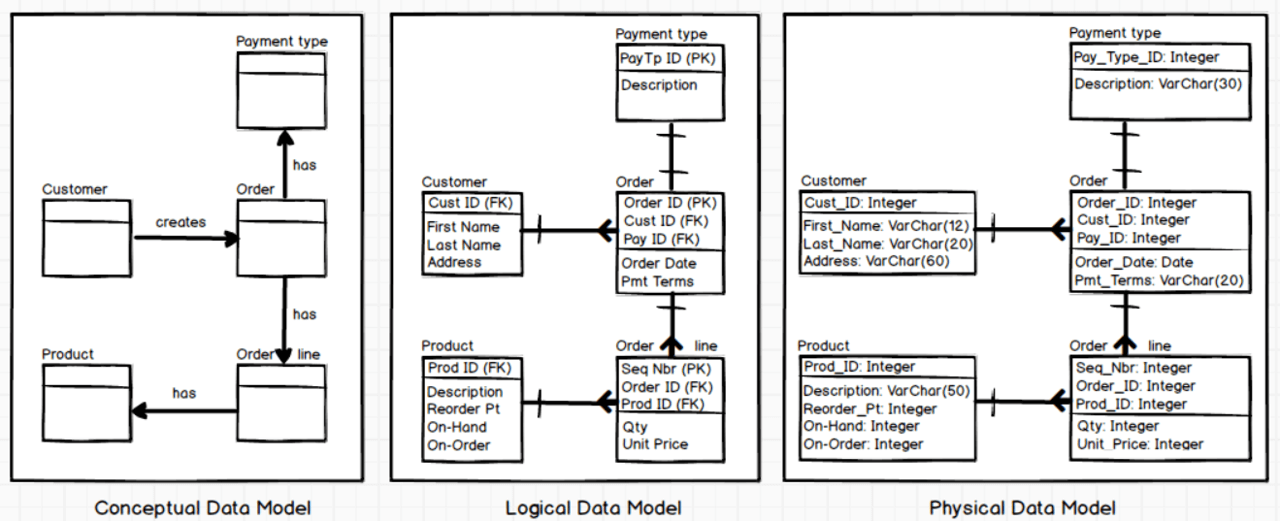
Hackolade Studio fully supports the traditional phases of conceptual, logical, and physical modeling, with a clear separation of logical (technology-independent) vs physical models.
Conceptual modeling is key to agree on scope and concepts, and to establish a shared language of business terms and definitions. By focusing on common terminology, it helps to prevent misunderstandings and it sets the foundation for clear communication, especially in large or cross-functional teams. Optionally each object can be linked with one or more terms from one or more business glossaries.
Logical modeling defines a neutral, unified data structure that transcends specific technologies, to capture the business rules necessary to ensure the integrity of the data. It serves as a blueprint for creating various physical models.
Physical modeling customizes the design for the technical specifics of each platform (e.g., relational databases, NoSQL, Graph databases, APIs, Big Data). This model ensures that the design works within the constraints of the chosen technology and optimizes implementation.
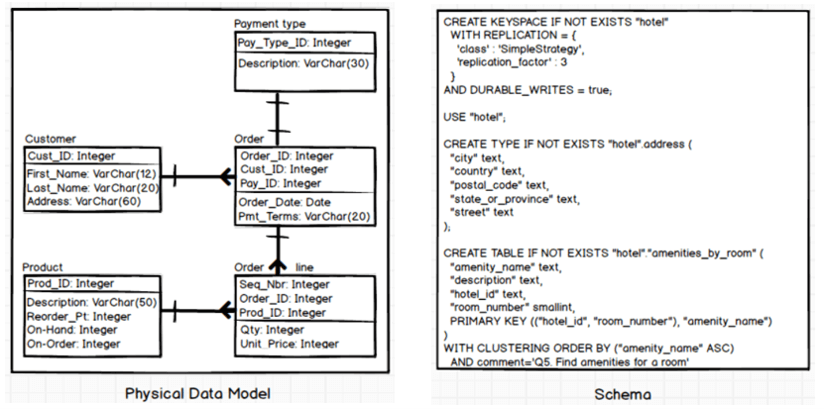
Core relational constructs
Hackolade Studio fully supports the modeling of core relational constructs, including entities/tables/views, attributes/columns/fields, primary keys and foreign key relationships with their cardinality, all of which are native elements of its ER diagramming and modeling approach across conceptual, logical, and physical layers.
Database objects such as stored procedures or functions, triggers, and sequences are handled at the physical level through properties, if supported by the target technology, and are forward-engineered in DDL generation and in integration into DevOps workflows. They can also be reverse-engineered from database instance or from DDLs. They are included in documentation generation.
The right-hand side displays the properties pane for any entity you select in the object browser or central pane. This is where you maintain the characteristics and constraints, including a detailed description, of each object.
Forward- and Reverse-Engineering
Speed up your modeling and development cycle

Forward-engineering
For RDBMS and SQL-like targets, the artifact is in the SQL dialect of the target technology, which may be ANSI SQL, or a variation thereof (for example T-SQL for SQL Server, Azure SQL, and Synapse.) For non-SQL targets, the syntax is according to the target's specifications.
Our models are stored natively in open JSON format, requiring no special export mechanism. Additionally, the generation of several other artifacts is possible, in JSON Schema, YAML, Excel, SQL DDLs, ArchiMate, dbt, schema syntax of the target technology, etc…
The tool helps create, manage, and evolve data models. It can generate/forward-engineer DDLs and ALTER scrips for changes in SQL databases, and scripts for 45+ other technologies.

Reverse-engineering
You can reverse-engineer from instance for each of the technology targets we support, including RDBMS, NoSQL, Avro, Parquet, ProtoBuf, Swagger/OpenAPI, GraphQL, respectively in each of their target plugins.
More generically across all targets, you can import:
- DDLs
- XML Schema (XSD) from ER/Studio or Erwin
- PowerDesigner
- GenAI in Mermaid ER code
- Collibra
- JSON Schema, plus infer schema from JSON files and YAML files
Engage the dialog
Collaborative application architecture design

A powerful tool for analysts, data architects, designers, developers, and DBAs
Evaluate alternatives, recognize potential hurdles early to reduce rework later. Facilitate troubleshooting and evolution to respond to growth and customer needs.

Data Models Repository
The Workgroup Edition brings a native integration with Git repositories for your data models. The Workgroup Edition makes it easy for users who are not so familiar with Git to leverage the tremendous power of this popular tool, and enable versioning, branching, change tracking, team collaboration, peer review, and other related capabilities.
It also facilitates Metadata-as-Code strategies.
Data model documentation
Publish data model details

HTML, Markdown, or PDF formats
Once you have enriched your model with descriptions, constraints, and relationships, Hackolade generates a rich configurable report including diagrams, tables, and all the metadata, plus other artifacts.
Data governance
Ensure data integrity and build credibility

Add just the right level of control
Combine the flexibility of the document model with true data conformance and validation capabilities. Now teams can benefit from the ease of development that the document model offers, while still maintaining the strict data governance controls that are critical for applications in regulated industries.
Data dictionary
Define once object definitions that can be re-used in multiple places. A library of definitions standardizes content and insures consistency. It also simplifies the work of data modelers so maintenance can be performed in one place and be automatically propagated to all places where the definition is referenced.
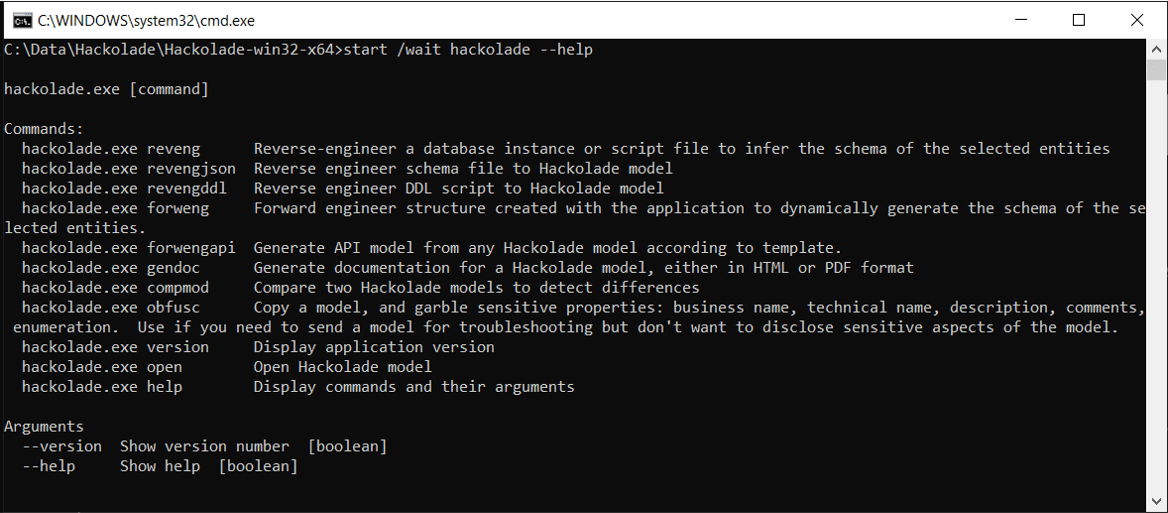
Command Line Interface
True support for an agile development approach leveraging the flexibility of NoSQL dynamic schemas via automated tasks to discover new fields and structures from a much larger dataset as a basis for document sampling.
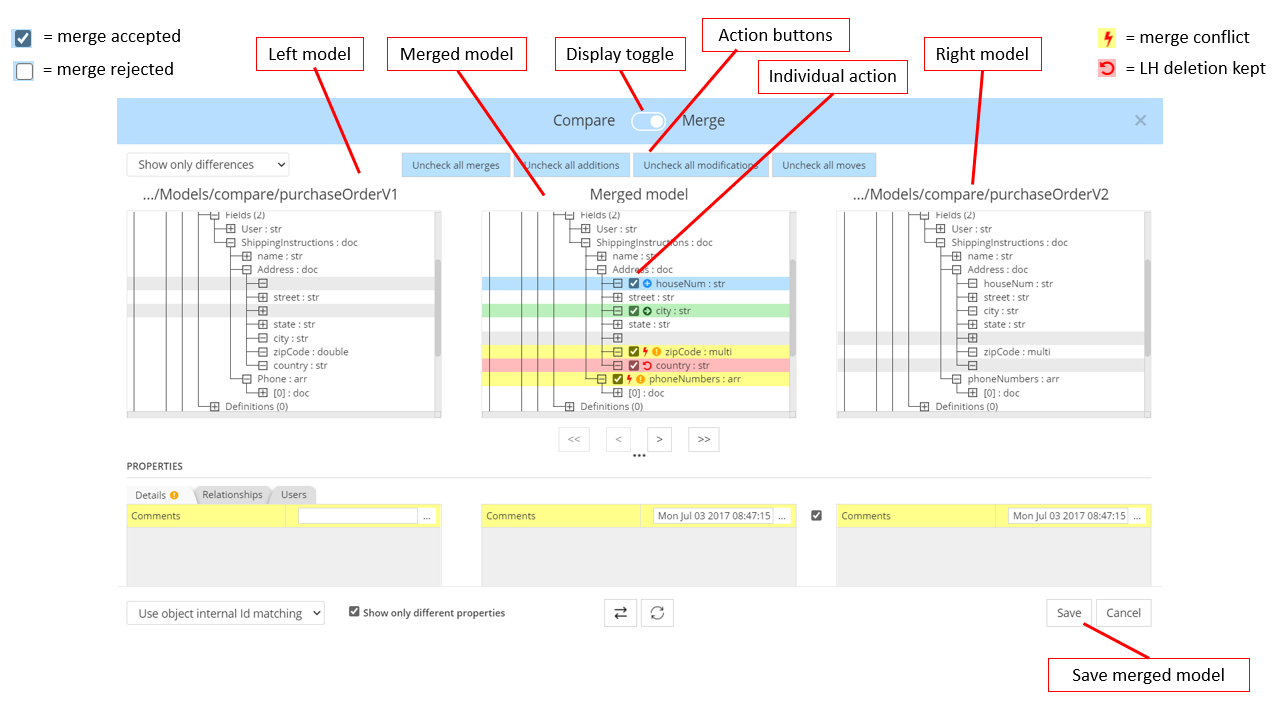
Model compare and merge
Identify additions, modifications, and deletions between 2 versions of a model, or between a baseline model and what can be found in the production database instance. Manual and automatic merging can be performed.
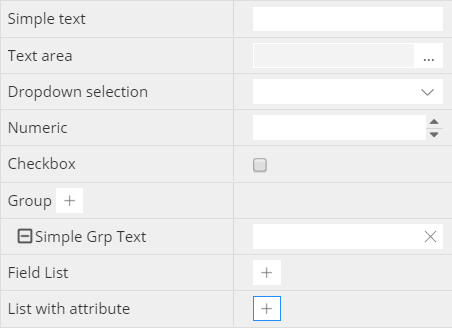
User-defined custom properties
To help fit Hackolade in your data management infrastructure, you may define your own properties for any kind of object: model, container, database, bucket, collection, table, or attribute.
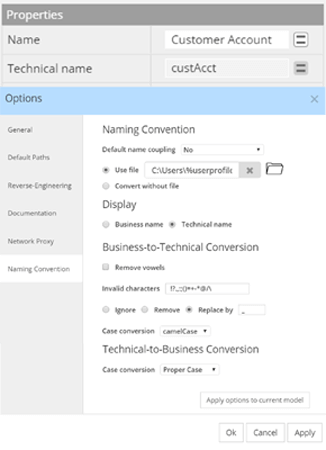
Naming conventions
You can maintain both a ‘business name’ and a ‘technical name’ for objects (containers, entities, and attributes.) To facilitate the maintenance of these 2 names, it is possible to keep them synchronized and transformed based on a set of user-driven parameters, and optionally based on a conversion file maintained outside of the application. Name conversion can go both directions: Business-to-Technical, or Technical-to-Business. Furthermore, when performing reverse-engineering, it is assumed that the database instance contains technical names, to be transformed in business names.
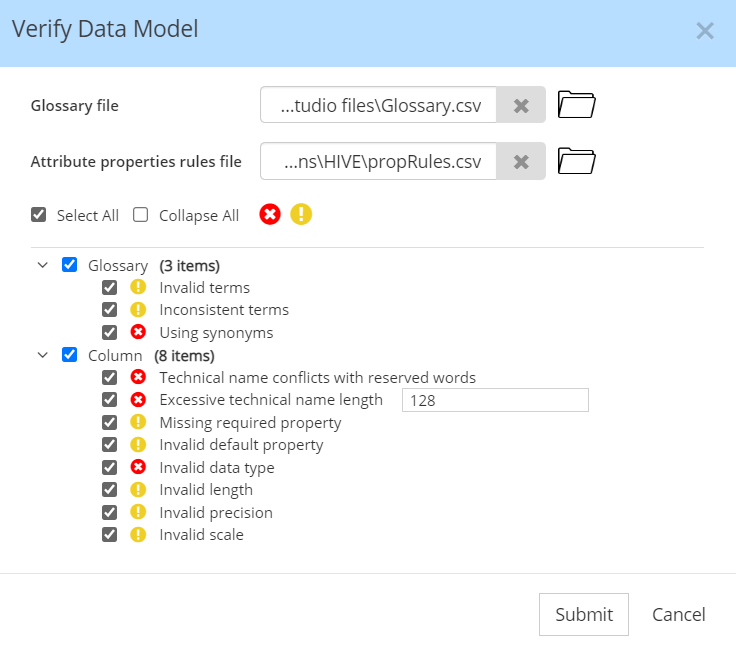
Data Model Verification
Verify the consistency and quality of data models according to a glossary of class terms and prime terms (optionally preceded by modifiers), and target-specific attribute rules such as precision/scale for numeric, and length for string data types.
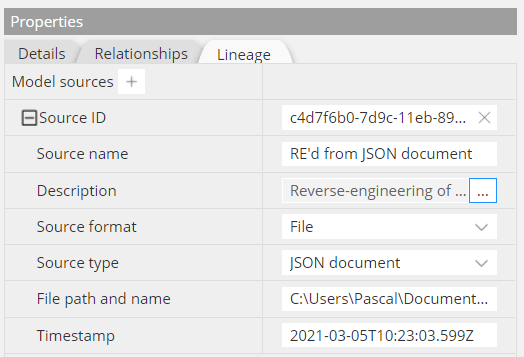
Lineage capture
Object lineage states where an object comes from, where it is going, and what (optional) transformations are applied to it as it flows through multiple processes. It helps understand the life cycle of the object. Lineage is the documentation of the life cycle.
Hackolade includes basic lineage capture capabilities to enable an audit trail, which can in turn be used to feed a specialized lineage tool where further visualization can be performed, or to feed an ETL tool where transformation can take place.

Bulk editing in Excel with export/import
For any of the supported targets, it is possible to export all or part of a model, so properties could be easily edited in a tabular format, to be re-imported back into the application. You may pick and choose exactly which objects and properties are exported for each target.

Model-driven API generation
Generate an OpenAPI (or Swagger) model and documentation from any Hackolade model target. This feature will help make your APIs more consistent than those produced by hand, while easily exposing resources for underlying data sources. API maintenance will be greatly facilitated, and Total Cost of Ownership reduced. Take an entity-relationship diagram (ERD) to automatically generate the API for CRUD operations of the entities of that data model.
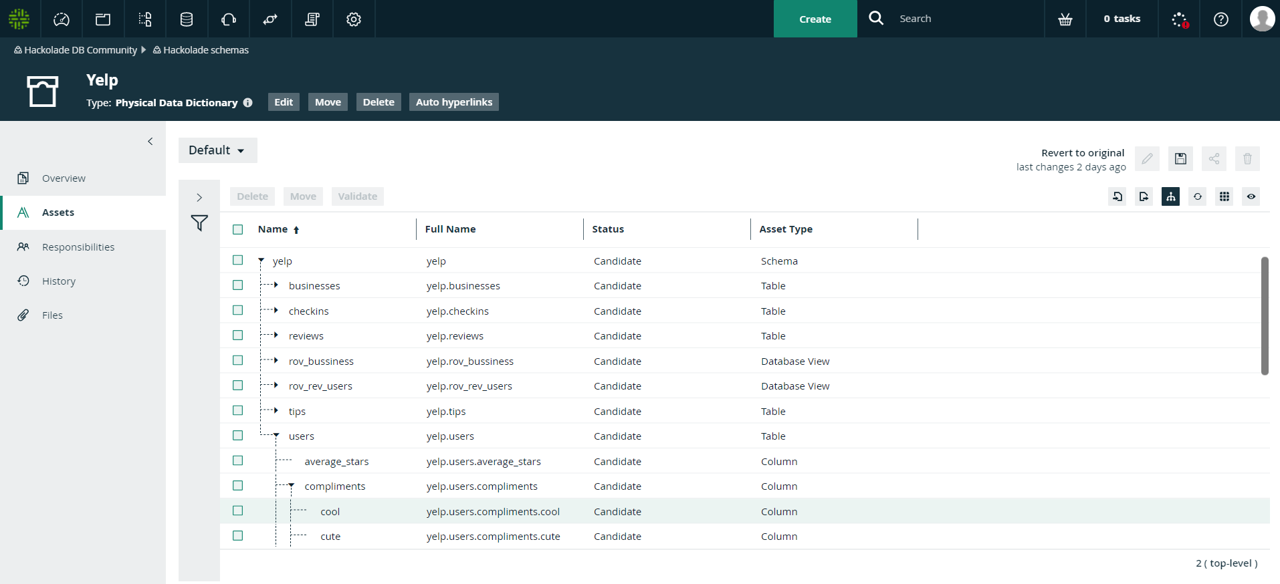
Native Collibra Data Dictionary integration
Hackolade uses the Collibra Core and Import APIs so users can easily publish their Hackolade data models into the Collibra Data Dictionary, for any of the technology targets supported by Hackolade.
In Collibra, users can view nested hierarchies and Entity-Relationship Diagrams for data models designed and maintained in Hackolade, or easily reverse-engineered from database instances.
Graphic visualization of complex data structures
Leverage the power of visual data modeling
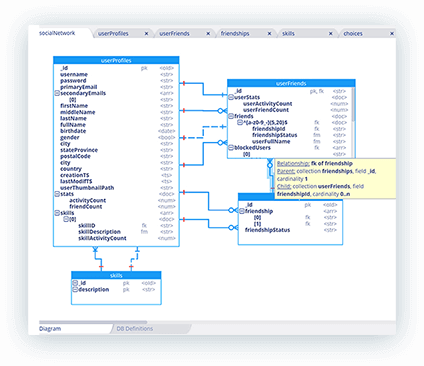
Intuitive and easy-to-use interface
Hackolade's user interface has been carefully designed to be clear and effective, minimizing the learning curve, and allowing you to start modeling right away, without the need to read the entire user manual.
Just enough industry standards
Entity Relationship theory and JSON Schema are great industry standards. Hackolade uses just enough of them to serve its purpose. But not too much of them either, so they don't become a constraint to the practical construction of NoSQL document models.
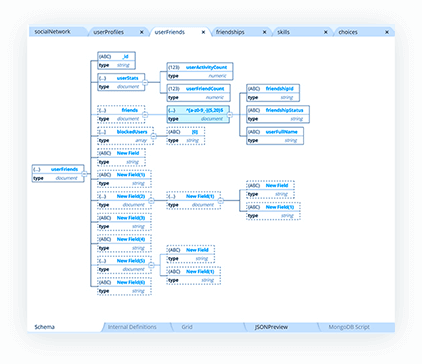
Visual ER diagrams for JSON documents
Schema design in a schemaless world seems like a contradiction. Hackolade applies some Entity Relationship theory to non-relational databases to represent denormalized data in a user-friendly way.
Graphic hierarchical schema editing
Hackolade is specifically designed to handle the powerful nature of nested objects, denormalization, and polymorphic semi-structured schemas. It uses a JSON Schema notation, easily visualized and maintained in a hierarchical schema view.
Leveraging the power of JSON and NoSQL
Modeling nested objects: sub-documents and arrays
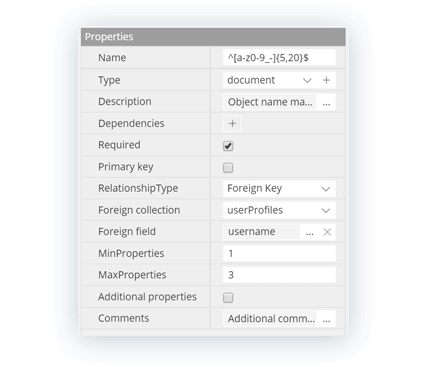
Field properties
Each data type has its specific properties and constraints, allowing documentation and validation of the business rules needed for proper data integrity. Following the capabilities of JSON, Hackolade supports polymorphic semi-structured schemas with mutiple types possible for a given field/attribute.
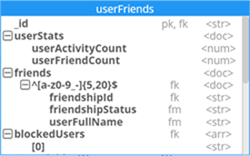
Collapsible hierarchical schema view
To make each collection's structure more readable, the ER diagram contains a pretty view of the collection schema with an indication of each field's data type. You can easily navigate the database structure only using a mouse.
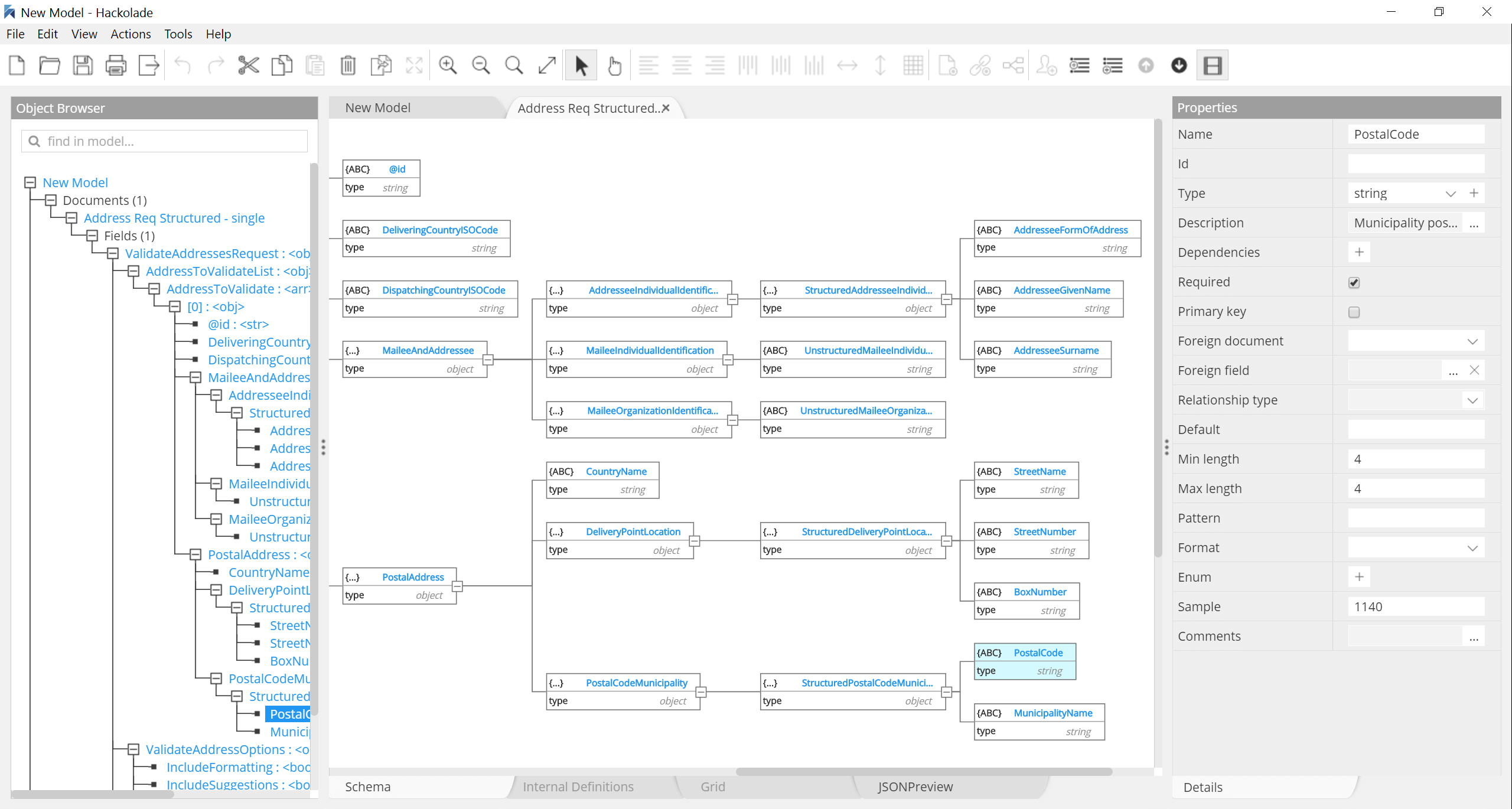
JSON Schema editor
You may use Hackolade to model plain JSON documents, with its intuitive graphical editor hiding the complexity of JSON Schema with no loss of power. It simplifies the visualization and understanding of deeply nested structures, and facilitates editing and maintenance. Hackolade dynamically generates a sample JSON document to illustrate the structure being built, and validates both the JSON Schema and the sample document.
Even non-relational DBs have relationships
Documentation of implicit relationships and denormalization
Denormalized data requires thorough updates
For RDBMS and SQL-like targets, the artifact is in the SQL dialect of the target technology, which may be ANSI SQL, or a variation thereof (for example T-SQL for SQL Server, Azure SQL, and Synapse.) For non-SQL targets, the syntax is according to the target's specifications.
Our models are stored natively in open JSON format, requiring no special export mechanism. Additionally, the generation of several other artifacts is possible, in JSON Schema, YAML, Excel, SQL DDLs, ArchiMate, dbt, schema syntax of the target technology, etc…
The tool helps create, manage, and evolve data models. It can generate/forward-engineer DDLs and ALTER scrips for changes in SQL databases, and scripts for 45+ other technologies.
Multi-platform desktop application
Native support for your desktop OS
Matching your environment
Hackolade was developed to be conveniently used on any of your desktop computers: Windows 7 through 10, Mac OS X 10.10 or higher, and several Linux flavors based on kernel v3.20 or above.