
Polyglot Data Modeling
In traditional data modeling for relational databases using the conceptual, logical, and physical types of models, the purpose for a logical model has been defined as a database-agnostic view of normalized structures and business rules.
It becomes quickly obvious that a logical model can only be technology-agnostic if and only if the target is strictly RDBMS. But as soon as you need for the logical model to be useful with other technologies, the strict definition of a logical model becomes too constraining. Given that Hackolade Studio supports so many technologies of databases and data exchanges that are not RDBMS, it was necessary to free ourselves from the strict constraints of the definition of logical models. To emphasize the differences, we found that using a different word was also necessary.
polyglot | \ ˈpä-lē-ˌglät \ : speaking or writing several languages : multilingual
Also with RDBMS vendors, the differences between the physical implementations are fairly minor, and so are the differences between the SQL dialects. Not so with all the targets supported by Hackolade for data-at-rest and data-in-motion. The feature set, the storage model, the terminology, the data types, the indexing capabilities, the schema syntax, etc.: there is very little in common between a MongoDB and a Cassandra data model, or between a Parquet and a Neo4j data model for example. The generation of physical names for entities (could be called tables, collections, nodes, vertices, files, etc.. in target technology) and attributes (could be called columns, fields, etc.. in target technology) should be capable of following different transformation rules, as Cassandra for example does not allow UPPERCASE while MongoDB will prefer camelCase, etc.
In our definition, a Polyglot Data Model is sort of a logical model in the sense that it is technology-agnostic, but with additional features:
- it allows denormalization, if desired, given query-driven access patterns;
- it allows complex data types;
- it generates schemas for a variety of technologies, with automatic mapping to the specific data types of the respective target technologies;
- it combines in a single model both a conceptual layer in the form of a graph diagram view to be friendly to business users, as well as an ER Diagram for the logical layer.
Physically, in the sense of storing on a disk, a polyglot model is a single atomic unit. It is not like the model files of other legacy tools that may contain both a logical and a physical model. Our model file does not contain multiple models. This is done on purpose and is viewed as a huge advantage that allows much of the modular architecture that sets our tool apart. Logically, it is this modular architecture that allows us to selectively derive so many very different models from a polyglot model. Or derive from (parts of) multiple polyglot models. Or derive a polyglot model from other polyglot model(s), etc... Or allow to put in place a Domain-Driven Data Modeling approach. While our different approach may surprise some veteran users of other tools, you will quickly appreciate the advantages.
Polyglot Data Modeling
Starting with version 5.2.0 of Hackolade Studio, users can now define structures once in a technology-agnostic polyglot data model, complete with denormalization and complex data types, then represent these structures in a variety of physical data models respecting the specific aspects of each target technology.
The polyglot functionality is there to help cope with the challenges of polyglot persistence. Polyglot persistence can be applied to different use cases, for example a large operational application:

or through a data pipeline:

For example, you want to make sure to keep in sync the structures of an operational database in MongoDB, a landing zone with Avro files on S3 object storage, a data lake on Databricks with bronze-silver-gold states, streaming with Kafka and a Confluent Schema Registry, and a data warehouse in Snowflake. It is hard enough to build this data pipeline, imagine what it takes to support to dynamic evolution of these schemas as new attributes are constantly added during the application lifecycle.
If you add/delete/modify entities or attributes in the polyglot model from which several target models are derived, all these changes can trickle down in the target models.
Flexibility
In a basic use case, you could have just one polyglot model, and several target models derived entirely from the common polyglot models. Each target model would just reflect the physical implementation for its respective technology. Entities can be deleted from the target model, others can be added, and the model can be enriched with entity options, indexes, etc. to generate the proper artifacts (script, DDL, ...) You may also deactivate attributes in the target model if they're not necessary, or you may modify some their properties.
But overall, the above use case is a bit theoretical, and reality will quickly dictate more flexible approaches. In a slightly more realistic use case, you could have target models that are each a different subset of a same polyglot model. Each target model may be supplemented by its own additional entities.
Elaborating further, you could derive a target model from multiple polyglot models, or subsets thereof:

Conceptual modeling
It is generally said that there are 3 categories of data modeling: conceptual, logical, and physical. In summary, conceptual modeling captures the common business language and defines the scope, whereas the logical model captures the business rules in a technology-agnostic manner, and the physical model represents the specific implementation of the model.
With version 6.6.0 of Hackolade Studio, we facilitate the process of conceptual data modeling by providing a Graph Diagram view to capture the entities and their relationships..

A conceptual model is created as part of a polyglot model. The Graph View lower tab of the central pane shows a graph visualization. It is also possible to use the ER Diagram tab of a polyglot model, or create an ERD View so that you can toggle the Display Options to show the desired level of details, for example with attributes and no data types, or with no attributes, etc...
For business glossary, Hackolade Studio currently leverages a CSV file as defined in the model verification page.
Logical modeling
Important: for users coming from traditional data modeling tools for RDBMS and the traditional process of conceptual, logical, physical, it may be tempting to use Hackolade's Polyglot models purely in the same way as before, and ignore the nuances and purpose of our Polyglot approach. Please don't, as you might be disappointed by the result. It would provide results similar to an exercise of using MongoDB with a normalized data model, i.e. not the optimal use of a NoSQL document database...
Note: for decades, it has been said that logical models were "technology-agnostic. All that works well enough using the famous rules of database normalization -- as long as your target technologies are relational only. But as soon as we're having to deal with NoSQL or with APIs and modern storage formats, it turns out that logical models which respect third normal form for many-to-many relationships with junction tables aren't "technology-agnostic" after all. In a NoSQL document database, you would embed information and not use any junction table. Similarly, supertypes/subtypes can be handled in NoSQL via polymorphism instead of inheritance tables, etc.
While our Polyglot model is truly technology-agnostic, it is also a common physical model with the following features:
- allows denormalization, if desired, given access patterns;
- allows complex data types;
- generates schemas for a variety of technologies, with automatic mapping to the specific data types of the respective target technologies.
Typically in logical models, you would have normalized entities, and you may denormalize in the physical model for performance. With a Polyglot model, it is advised to do things the other way around. You should use query-driven access patterns to define Polyglot structures with complex data types, including denormalization and polymorphism. When you derive to an RDBMS target, you will want to let our process normalize the structure on-the-fly, while you will want to keep the hierarchical structure for technology targets that allow it.
Supertypes and subtypes
Also known as superclasses and subclasses. Hackolade Studio will let you create supertypes and subtypes in a Polyglot model, following either the traditional method:

or a denormalized method, with a complex sub-object as well as a oneOf choice representing different possible sub-types for inheritance

Either way, the application will understand, depending on the target technology and its capabilities, whether to normalize with inheritance tables, or denormalize for NoSQL and leverage polymorphism.
Many-to-many relationships
With logical models having to be normalized, they are only "technology-agnostic" if their use is limited to relational databases, as explained above. With NoSQL databases allowing for denormalization with embedded objects and arrays, no junction tables are necessary to represent many-to-many relationships.
Therefore, our Polyglot data models have a more intuitive way of documenting a many-to-many business rule:

And our automatic normalization function, when deriving the Polyglot model to a relational database, will generate the expected junction table:

Conversely, the derivation to a NoSQL target will leave the entities as declared in the Polyglot model and allow for further denormalization according to the needs of the access patterns. Ideally, the denormalization takes place directly in the Polyglot model.
More information about the philosophy behind our Polyglot Data Model concept can found on this page.
This other page details how to use polyglot data models.
Lineage and impact analysis of changes
Once a target model has been created and derived from a polyglot model, it contains all the derived objects. You may make some changes to the target model:
- make changes to the properties of entities and attributes without changing them in the polyglot model. This is used if you need minor deviations;
- add new entities and views that are specific to the physical target model, for example based on access patterns;
- remove entities from the target model. This action does not delete the entity in the polyglot model;
- add, delete or modify attributes, again without effect on the Polyglot model.
You may also join entities from multiple polyglot models by repeating the operation to derive from polyglot.
You may supplement the target model with metadata, index and partitioning information specific to the target technology, then forward-engineer artifacts according to your use case.
An impact analysis dialog is displayed to let you decide which objects to include as part of this refresh operation. Maybe these objects were not selected originally, or they could have been added to the polyglot model since the previous refresh or derive operation, or they could have been deleted in the target model.
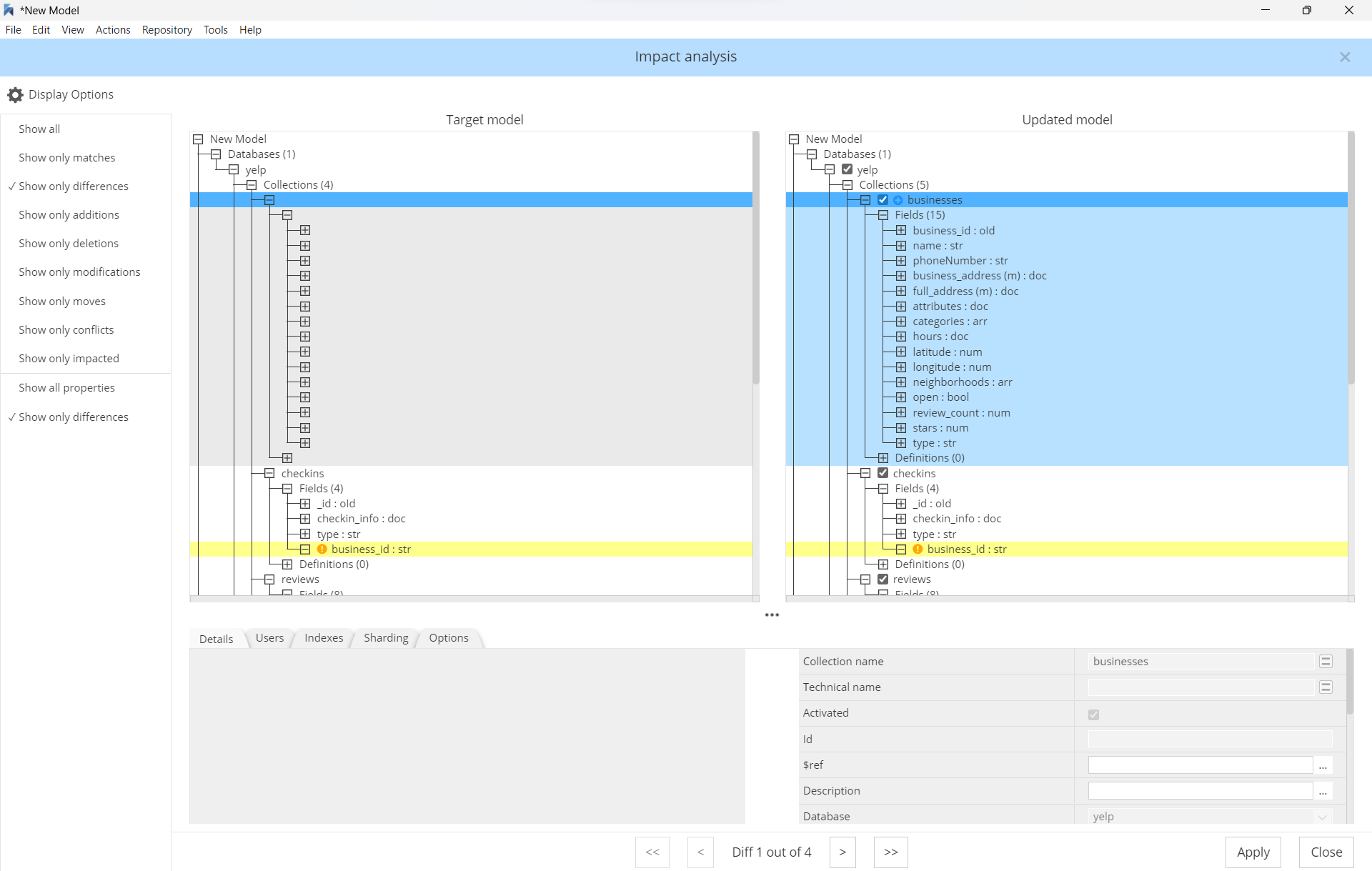
The Highlight section on the left displays a legend of the colors. It also allows you to select the differences you want to display or hide:
- Modifications in Polyglot since last update (yellow)
- Deviations in Target (green). Deviations in Target (green) are not highlighted by default to avoid noise and confusions
- Additions in Polyglot (blue)
- Deletions in Polyglot (red)
When opening a target model with a reference to one or more polyglot models, you are presented with the option to update the objects.
You may also permanently break the connection to the polyglot model. This operation should be done with care of course, as it cannot be re-established afterwards without restarting all the steps from scratch. The operation replaces all references to the objects of the polyglot model by the objects themselves. But further modifications in the polyglot model will no longer have any effect in the target model.