
Couchbase
Couchbase Server is an open-source, distributed multi-model NoSQL document-oriented database software package that is optimized for interactive applications. It has a long history and evolution. It natively manipulates data in key-value form or in JSON documents. Nevertheless Couchbase may be used to store non-JSON data for various use cases.
Hackolade Studio was specially adapted to support the data modeling of multiple object types within one single bucket, while supporting multiple buckets as well. The application closely follows the terminology of the database.
The data model in the picture below results from the reverse-engineering of the sample travel application described here.

Buckets
There is a fundamental difference with many other NoSQL document databases: Couchbase strongly suggests to store documents of different kinds into the same "bucket". A bucket is equivalent to a database. Objects of different characteristics or attributes are stored in the same bucket. It may seem counter-intuitive when moving from a RDBMS or MongoDB, but records from multiple tables should be stored in a single bucket, with a “type” attribute to differentiate the various objects stored in the bucket.
Most deployments have a low number of buckets (usually 2 or 3) and only a few upwards of 5. Although there is no hard limit in the software, the maximum of 10 buckets comes from some known CPU and disk IO overhead of the persistence engine and the fact that Couchbase allocates a specific amount of memory to each bucket.
But having multiple buckets is something that can be quite useful for different use cases:
- multi-tenancy: you want to be sure all data are separated
- different types of data: you can for example store all documents (JSON) in one bucket, and use another one to store "binary" content. The setup would have a bucket with views, and the other one without any.
- for data with differing caching and RAM quota needs, compaction requirements, availability requirements and IO priorities, buckets act as the control boundary.
For example, if you choose to create 1 replica for medical-codes data that contain drug, symptom, and operation codes for a standard based electronic health record. This data can be recovered easily from other sources, so a single replica may be fine. However, patient data may require higher protection with 2 replicas. To achieve better protection for patient data without wasting additional space for medical-codes you could choose separate buckets for these 2 types of information.
There are 2 types of buckets, each with its properties: Couchbase buckets and Memcached buckets.
Documents
A document refers to an entry in the database (other databases may refer to the same concept as a row). A document has an ID (primary key in other databases), which is unique to the document and by which it can be located. The document also has a value which contains the actual application data.
Documents are stored as JSON on the server. Because JSON is a structured format, it can be subsequently searched and queried.
Document kind
When mixing different types of objects into the same bucket, it becomes necessary to specify a "type" attribute to differentiate the various objects stored in the bucket. In Hackolade Studio, each Document Kind is modeled as a separate entity or box, so its attributes can be defined separately. A specific attribute name must be identified to differentiate the different document kinds. The unique key and the document kind field are common to all document kinds in the bucket, and displayed at the top of each box in the ERD document:

Keys
Another modeling characteristic distinguishes Couchbase from some other NoSQL document databases: the unique key of each document is stored 'outside' the JSON document itself. Couchbase was originally a key-value store. With version 2.0, Couchbase bridged the gap to being a multi-model database supporting JSON documents. In essence, the key part remains, and the value part can also be a JSON document. The fundamental difference is that a pure key-value database doesn't understand what's stored in the value, while a document database understands the format in which documents are stored and can therefore provide richer functionality for developers, such as access to documents through queries.
Couchbase does not automatically generate IDs. Document IDs are assigned by the software application. A valid document ID must:
- Conform to UTF-8 encoding
- Be no longer than 250 bytes
Users are free to choose any ID for their document, so long as they conform to the above restrictions. This feature can be leveraged to define natural keys where possible, so they can be human-readable, deterministic, and semantic.
Flexible key design
Starting with v7.5.0, you may now define the structure of your primary key with a flexible design using existing constants, patterns, separators, and existing fields. This capability allows you to implement strategies illustrated on this page.
In a basic use case, you could have a simple document key made of single unique identifier. Unique identifiers could be natural keys, for example an email address. The advantage is that their contextual meaning is well understood by humans and as a result are predictable. But they are less flexible in the case for example when the value must change for the same document, for example if a user changes email address. Unique identifiers can also be surrogate keys, where a meaningless unique identifier like a UUID is used as the key. It may be unpredictable and harder to read or type, but it is more scalable and flexible.
With this flexible key design, it is now possible to structure a composite key (a.k.a compound key) and assemble multiple segments. For example, given this document model:
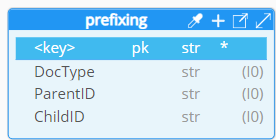
and the defined PK structure:
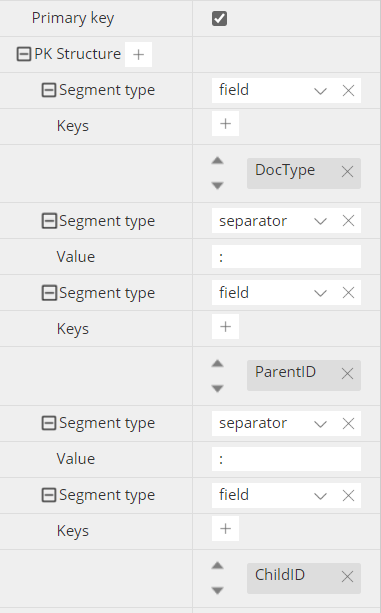
an example of key could be this:

You may define PK Structure using 4 types of segments: constant, field, separator, and regex pattern. There is no theoretical limit to the number of segments, but the total length of the key cannot exceed 250 bytes. If you use a numeric field for a segment, it should ideally be an integer, and ti will be converted to a string (as the key can only be of string data type.
Typical separators for Couchbase are column (:), double column (::) or hash (#). Separators are not mandatory, but they are strongly recommended, at least between fields, as they facilitate parsing, and inference during reverse-engineering.
Attributes data types
Couchbase attributes support standard JSON data types, including lists and sets (arrays), and maps (objects). The Hackolade menu items, contextual menus, toolbar icon tooltips, and documentation are adapted to Couchbase's terminology and feature set. The following words are reserved.
Hackolade was specially adapted to support the data types and attributes behavior of Couchbase.

Indexes
An index is a data-structure that provides quick and efficient means to query and access data, that would otherwise require scanning a lot more documents. Couchbase Server provides different types of indexes, as documented here. .
Hackolade supports the creation, documentation, forward- and reverse-engineering of:
- Primary: Provided by the Index Service, this is based on the unique key of every item in a specified bucket. Every primary index is maintained asynchronously. A primary index is intended to be used for simple queries, which have no filters or predicates.
- Secondary: Provided by the Index Service, this is based on an attribute within a document. The value associated with the attribute can be of any type: scalar, object, or array. A Secondary Index is frequently referred to as a Global Secondary Index, or GSI. This is the kind of index used most frequently in Couchbase Server, for queries performed with the N1QL query-language.
Views (TBA)
Views and indexes support querying data in Couchbase Server. Querying of Couchbase data is accomplished via the following:
- MapReduce views accessed via the View API.
- Spatial views accessed via the Spatial View API.
- N1QL queries with Global Secondary Indexes (GSI) and MapReduce views.
There are a number of differences between views and GSIs. At a high level, GSIs are built for N1QL queries, which are great for supporting interactive applications that require fast response times. Views, on the other hand, provide sophisticated user defined functions to provide great flexibility in indexing. Views can support complex interactive reporting queries with a pre-calculated result.
More information on views can be found here.
Reverse-Engineering
The connection is established using a connection string including (IP) address and port (typically 8091), and authentication using username/password if applicable.
The Hackolade process for reverse-engineering of Couchbase databases is different depending on the Couchbase version. For versions 3.x, the indexed views are queried via the REST API. Starting with version 4.0, Hackolade uses N1QL syntax to perform the statistical sampling followed by the schema inference. And starting with version 4.5 Enterprise edition, Hackolade leverages the INFER statement.
For more information on Couchbase in general, please consult the website.
Forward-Engineering
For those developing Node.js applications on top of a Couchbase database, you may want to leverage the object document mapper (ODM) Ottoman that allows you build what your object model would look like, then auto-generate all the boilerplate logic that goes with it. Hackolade dynamically generates the Ottoman script based on model attributes and constraints. More information on Ottoman here and here.
We provide a sort of "forward-engineering by example", with an automatic JSON data sample generation. The script also includes the creation of indexes, and it can be applied to the database instance, provided that appropriate credentials are granted to the user. If the specified bucket does not exist, we attempt to create it.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.

A possible alternative could be to implement soft validation using the Eventing feature, which has been available since release 5.5.
With Eventing, one defines a javascript function that gets called with every document mutation. That function can do any of the following:
- log output to a data file
- create documents in a separate bucket
- run N1QL commands
An Eventing function can be deployed, then un-deployed once it has processed all the current documents, so one could get a snapshot of whether the current document set matches the established schema. It need not run all the time, unless schema validation is terribly important.
Also, one can deploy the Eventing service on additional nodes so that Eventing does not impact the performance of the rest of the cluster. Fitting with the philosophy of Couchbase, it provides *eventual* validation.
/////////////////////////////////////////////////////////////////////////////////////////////////
// SCHEMA VALIDATION FUNCTION
//
// This function will monitor the documents in a bucket and send errors to the output file and
// target bucket when a new or modified document doesn't match any of the provided schemas.
//
// This is a very simple implementation, supporting only name/type validation. It does not yet
// support any value validation (e.g., enumerations, array length constraints, string pattern
// matching, etc. etc.).
//
// You must specify an array of one or more valid schemas in the "get_top_level_schema()" function
// below.
//
// You may also specify two options in the functions immediately below.
//
// The first indicates whether to raise an error when fields are seen that do not exist in the schema.
//
// The second relates to schemas generated by Couchbase's INFER statement, where properties have a "%docs"
// field that indicates in what percentage of documents a property was seen. When set to 'true', this
// option treats properties with "%docs": 100 as required.
//
// Disclaimer: THIS SAMPLE CODE IS PROVIDED "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING
// THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
/////////////////////////////////////////////////////////////////////////////////////////////////
function test_for_extra_fields() {return(false);} // should we raise an error when seeing fields not in the schema?
function treat_100pc_as_required() {return(true);} // are fields listed as %docs: 100 in the INFER schema required?
function OnUpdate(doc, meta) {
var errors = [];
log("doc",doc);
try {
// sanity check, make sure we have some schemas to test with
var top_level_schema = get_top_level_schema();
if (!top_level_schema || !top_level_schema.length) {
log("Invalid schema, unable to validate document: " + JSON.stringify(top_level_schema));
return;
}
// loop through the schema flavors in the top level schema and see if
// we can find a match for the document
var matched = false;
for (var i=0; i<top_level_schema.length; i++) {
var res = validateDocAgainstSchema(doc,top_level_schema[i],"");
if (res != null) {
errors.push({"schema": i + top_level_schema[i].Flavor, error: res});
}
else {
matched = true;
break;
}
}
if (!matched) {
log("no match")
target[meta.id] = errors;
}
} catch (e)
{
log("Error checking schema.",e);
}
}
// not used
function OnDelete(meta) {
}
/////////////////////////////////////////////////////////////////////////////////////////////////
//
// validateDocAgainstSchema
//
// given a document and a json-schema structure, determine if the
// document matches the schema. This function is compatible with
// the extensions to json-schema used by the N1QL INFER command,
// though it does not require them.
//
function validateDocAgainstSchema(doc,schema,path) {
// sanity checks
if (doc == null)
return([{"generalError": "doc is null"}]);
else if (schema == null)
return([{"generalError": "schema is null"}]);
// it's possible for docs to be primitive values, or objects. Do basic type checking
// we need two tests for string types
else if (typeof doc == "string" || doc instanceof String) {
if (schema.type != "string")
return([{"typeError": "For path: " + path + ", schema specified type: " + schema.type + ", found string" }]);
}
// typeof will tell us the name of the type, except for arrays
else if (schema.type != typeof doc && schema.type != "array")
return([{"typeError": "For path: " + path +", schema specified type: " + schema.type +
", found type: " + typeof doc}]);
else if (schema.type == "array" && !Array.isArray(doc))
return([{"typeError": "For path: " + path + ", schema specified type: array, found type: " + typeof doc}]);
// if we have an array, each element of the array must match one of the types in the "items" list of schemas
if (schema.type == "array") {
var schemas = schema.items;
if (!Array.isArray(schemas)) // simplify by making sure items is an array
schemas = [schemas];
var failedItems = [];
// check each element in the array
for (var item=0; item < doc.length; item++) {
var itemMatched = false;
for (var subschema = 0; subschema < schemas.length; subschema++)
if (!validateDocAgainstSchema(doc[item],schemas[subschema])) {
itemMatched = true; // no errors, we found a match
break;
}
if (!itemMatched)
failedItems.push(doc[item]);
}
if (failedItems.length > 0)
return([{"typeError": "For path: " + path + ", some array elements didn't match any schema for that array.",
"invalidElements": failedItems, "schemas": schema.items}]);
}
// if we have an object, each field in the doc must match a property in the schema, and vice versa
else if (schema.type == "object") {
var missing_fields = [], extra_fields = [], bad_type_fields = [];
// make sure all the document's fields are in the schema
if (test_for_extra_fields()) for (var field in doc)
if (!schema.properties.hasOwnProperty(field)) // field not found in schema
extra_fields.push(path + field);
// now check the fields in the schema, test for existence, type match
for (var field in schema.properties) {
// don't count missing fields that only appear is some documents, i.e., %docs < 100
var required = false;
if ((schema.required && schema.required.indexOf(field) >= 0) ||
(treat_100pc_as_required() && schema.properties[field].hasOwnProperty('%docs') && schema.properties[field]['%docs'] == 100))
required = true;
if (!doc.hasOwnProperty(field) && required)
missing_fields.push(path + field);
else if (doc.hasOwnProperty(field)){
var type_check = validateDocAgainstSchema(doc[field],schema.properties[field],field + ".");
if (type_check)
bad_type_fields = type_check;
}
}
if (missing_fields.length || extra_fields.length || bad_type_fields.length) {
var errors = [];
if (missing_fields.length)
errors.push({"path:": path, "missing fields: ": missing_fields});
if (extra_fields.length)
errors.push({"path:": path, "extra fields: ": extra_fields});
if (bad_type_fields.length)
errors.push.apply(errors,bad_type_fields);
return(errors);
}
}
return(null); // no problems if we get this far
}
/////////////////////////////////////////////////////////////////////////////////////////////////
//
// get_top_level_schema
//
// This function returns an array of one or more json-schema's against which all
// documents will be validated.
//
function get_top_level_schema() {
return(
[
{
"#docs": 814,
"$schema": "http://json-schema.org/schema#",
"Flavor": "`type` = \"beer\", `upc` = 0",
"properties": {
"abv": {
"#docs": 814,
"%docs": 100,
"samples": [
0,
5,
6,
6.25,
8
],
"type": "number"
},
"brewery_id": {
"#docs": 814,
"%docs": 100,
"samples": [
"anchor_brewing",
"anderson_valley_brewing",
"budjovick_mansk_pivovar",
"magic_hat",
"wild_duck_brewing"
],
"type": "string"
},
"category": {
"#docs": 616,
"%docs": 75.67,
"samples": [
"British Ale",
"German Lager",
"North American Ale",
"North American Lager",
"Other Style"
],
"type": "string"
},
"description": {
"#docs": 814,
"%docs": 100,
"samples": [
"Stiegl Weizengold. It has 12o ...",
"An Ale Brewed with Honey\r\nOur ...",
"Help us celebrate American Ind...",
"Mogul is a complex blend of 5 ...",
""
],
"type": "string"
},
"ibu": {
"#docs": 814,
"%docs": 100,
"samples": [
0,
36,
55
],
"type": "number"
},
"name": {
"#docs": 814,
"%docs": 100,
"samples": [
"Braggot",
"Imperial Sasquatch",
"Our Special Ale 1992",
"Samson Crystal Lager Beer",
"Winter Solstice Seasonal Ale 2..."
],
"type": "string"
},
"srm": {
"#docs": 814,
"%docs": 100,
"samples": [
0,
6
],
"type": "number"
},
"style": {
"#docs": 616,
"%docs": 75.67,
"samples": [
"American-Style Amber/Red Ale",
"American-Style Lager",
"German-Style Pilsener",
"Light American Wheat Ale or La...",
"Old Ale"
],
"type": "string"
},
"type": {
"#docs": 814,
"%docs": 100,
"samples": [
"beer"
],
"type": "string"
},
"upc": {
"#docs": 814,
"%docs": 100,
"samples": [
0
],
"type": "number"
},
"updated": {
"#docs": 814,
"%docs": 100,
"samples": [
"2010-07-22 20:00:20",
"2010-12-20 15:32:12",
"2011-04-17 12:25:31",
"2011-08-15 11:53:48",
"2011-08-15 11:56:18"
],
"type": "string"
}
},
"type": "object"
}
]
);
}