
Model Hub solution architecture
The Hackolade Model Hub is a model-driven metadata collaboration platform that offers centralized, streamlined access to your Hackolade Studio data models, stored across one or more Git repositories. A model-driven metadata collaboration platform allows organizations to retake control of their data.
Like other catalogs, data dictionaries, and metadata management tools, the Hub maintains a comprehensive inventory of your data assets in order to deliver valuable insights. These insights are essential in driving an organization’s shift toward a data-centric culture, enhancing data discoverability, promoting data literacy, supporting governance, and fostering collaboration.
The Hub provides a map to help users navigate through and make sense of their organization’s complex data environment. It encourages consistency, accuracy, and completeness throughout the data landscape.
What sets our Hub apart is its proactive, model-driven foundation.
Traditional data catalogs
Traditional solutions adopt a reactive approach: collecting metadata from data sources after the fact, and attempting to tidy it up using tags, classifications, and redundancy checks, sometimes assisted by machine learning and artificial intelligence. While this strategy may seem appealing, especially when dealing with large datasets built without prior planning (remember "Big Data"?), it ultimately reinforces a cycle of retroactive cleanup rather than addressing the root causes of inconsistencies, redundancies, and other quality issues.
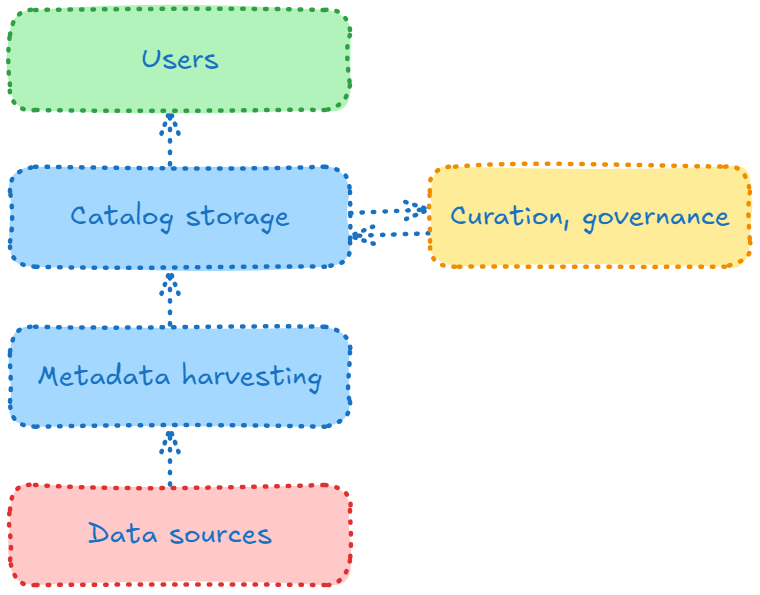
Traditional tools begin with data that accumulated without deliberate design. They harvest (a;k;a; crawl, discover, extract, infer, or ingest) metadata from diverse sources and then ask users, sometimes aided by AI, to untangle the resulting inconsistencies, inaccuracies, and duplication. Although teams can attempt to correct the catalog, define rules, and set standards, pushing those fixes into production systems is difficult when IT staff sit in other departments or external service lines. In practice, governance, policy-setting, and data cleanup all happen after the data is created, leaving everyone in perpetual catch-up mode.
Shift-left, proactive, design-first
Our approach is fundamentally proactive and the process flips that sequence. The Hackolade Hub is built on a design-first philosophy that engages subject-matter experts early in the process. Such shift-left strategy improves data quality and consistency from the outset, reduces rework, and ensures stronger alignment across teams. It also bridges the gap between technical implementations and the business-facing data catalog, fostering better collaboration through a shared understanding of the meaning and context of data.
While the process can be proactive for green-field applications and their databases and data exchanges, our approach is not limited to that use case. In many cases, organizations will want to first understand what they have -- their existing databases and APIs.
Reverse-engineer (or harvest metadata from sources)
A design-first approach can still be applied to existing datasets, but its real power is in transforming future work: every subsequent evolution is planned with clear models, eliminating the root causes of inconsistency and poor quality rather than merely treating the symptoms. We called this process "reverse-engineering", and it is equivalent to the harvesting process of traditional data catalogs. The difference is that we reverse-engineer into a data model, then replicate the data model into the read-only Hub database. The difference is fundamental in the sense that it shifts the location of where corrections and annotations occur -- the data model --, and who carries out those changes -- data architects and data modelers. Such a shift is necessary to avoid that corrections remain strictly in the catalog. This is the start of the virtuous circle whereby adjustments to the data model can not only be immediately visible in the Hub, but the model can be used to forward-engineer into the data sources, as described further down.
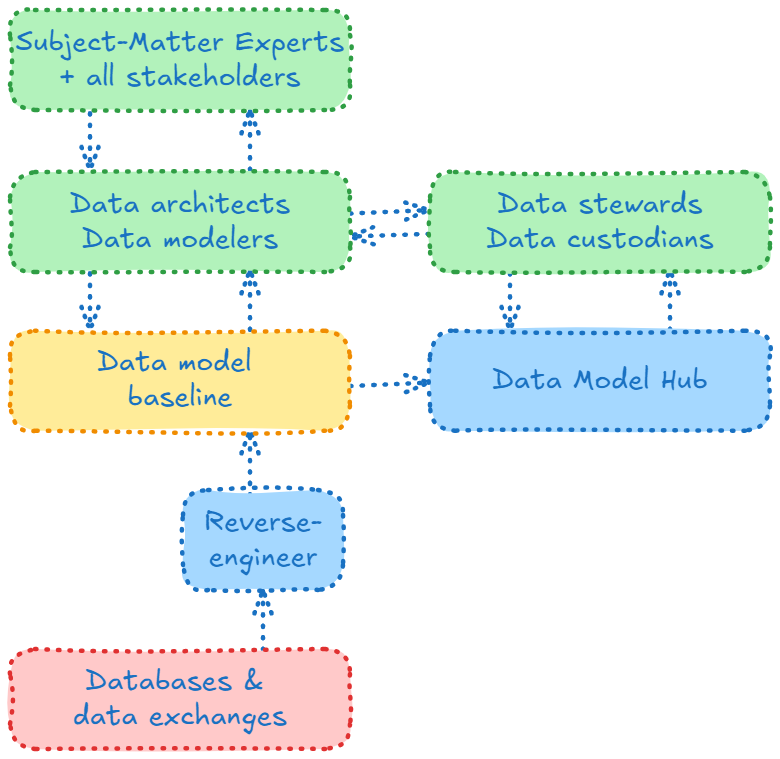
As applications inevitably evolve, such evolution is an opportunity to curate the source. That strategy could be called "Clean-as-you-Design" the next evolution, as inspired by the Clean-as-you-Code strategy in development. When you add new columns to existing tables, or new tables, and need to comply to quality standards, this exercise is an opportunity to fix issues in the existing model and gradually improve the overall quality of the metadata. Realizing that an ambition to solve all quality problems in all places at the same time may not be realistic, this approach meets continuous improvement objectives.
Forward-engineer to data sources
Whether for new databases or for existing ones, the forward-engineering process is something we've been doing for many years with Hackolade Studio, so data architects and data modelers are very familiar with the process:
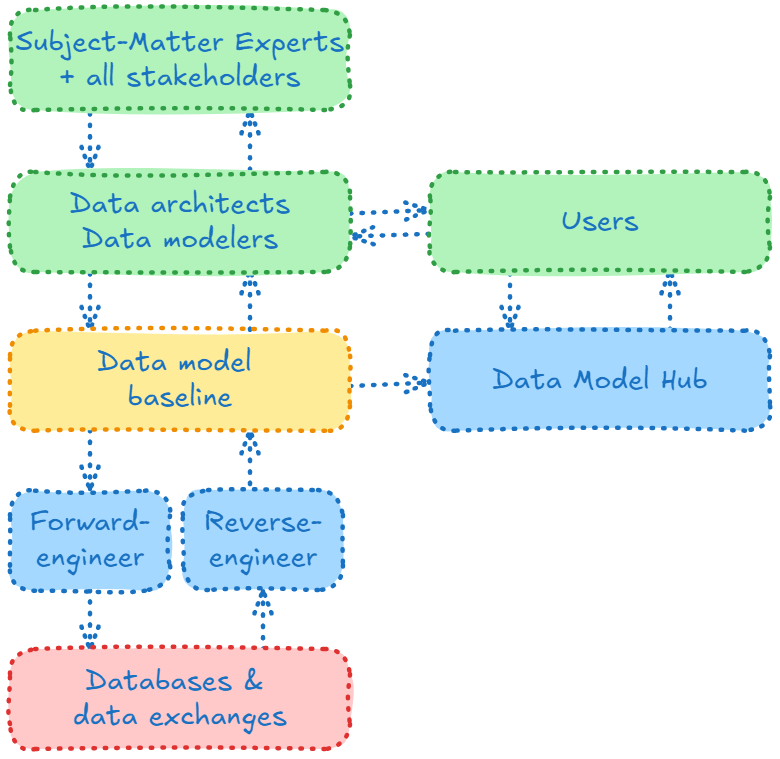
We start with application stakeholders and subject-matter experts, i.e.; the people who know the business and its needs. Together they agree on scope, vocabulary, concepts, and definitions. Data architects and data modelers then formalize those agreements into models and metadata before applications are developed and data is generated. Constraints are clarified, quality principles established, and processes put in place so that, from day one, it is high-quality data that is produced. There are interactions are at levels.
Retake control of your data
The Hackolade Enterprise Model Hub helps organizations retake control of their data (and reduce your data debt) by structuring how it’s designed, documented, governed, and understood. By enabling a design-first, model-driven approach, it improves data quality from the start, reducing cleanup costs, minimizing risk, and accelerating time to value. It turns scattered data into a strategic asset, aligned across both business and technical teams.
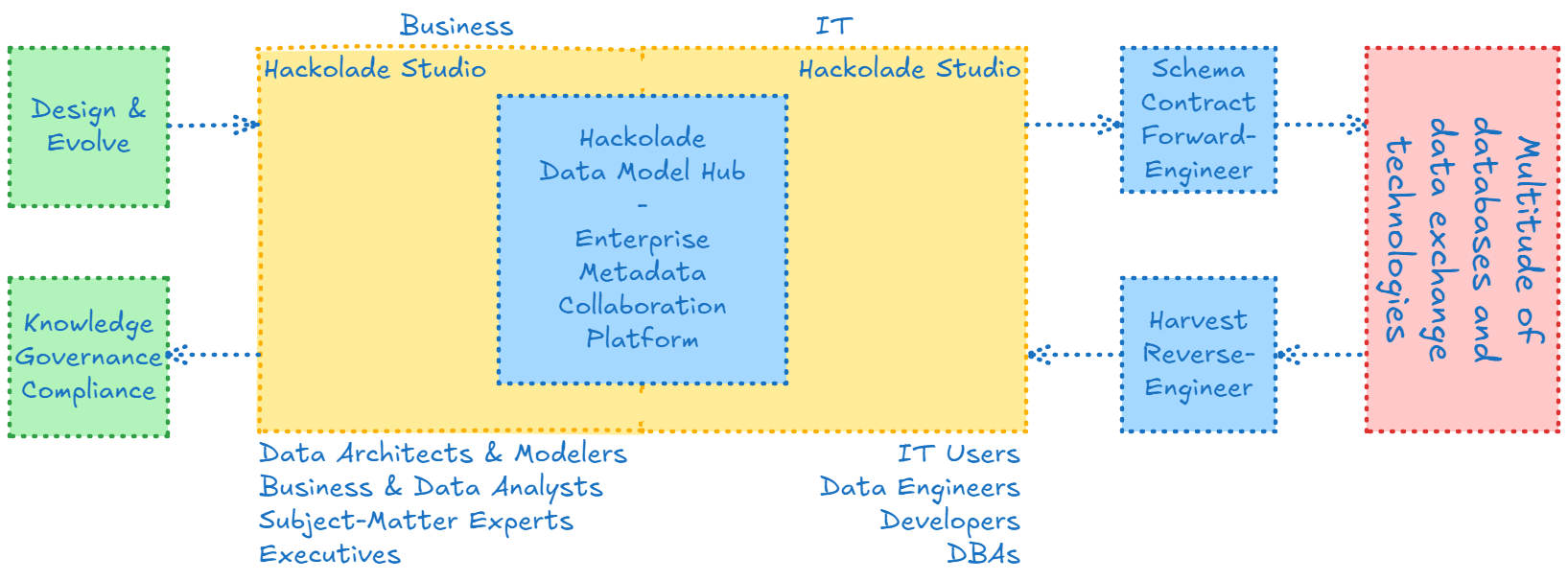
Traditional metadata management solutions and the Model Hub aim for the same goals and manage similar content. But they take fundamentally different approaches in terms of strategy, sequence, and execution.
Metadata provides structured information about data, and can be categorized into four main types:
- Business metadata: Definitions, identifiers like names and descriptions, classification and tags that help users locate and understand data assets.
- Technical metadata: Details on data types, formats, and structures that describe how data is organized and stored.
- Operational metadata: Reference information about data sources, relationships, profiling, and lineage that adds context and traceability.
- Governance metadata: Administrative layer with details such as data ownership, privacy, security, and usage policies.
Trying to clean up metadata after harvesting it from existing sources results in a very different level of quality compared to proactively planning, aligning on definitions, and setting clear guidelines from the outset.
When a data steward or any data citizen identifies an issue in the catalog or proposes governance measures or policies to improve data quality, simply updating the catalog isn't enough. A far more effective approach is to adjust the underlying data model, which directly influences how future data is created. This more proactive approach makes quality improvements stick, and ensures that the changes directly shape the data being produced.