
Integrate the CLI with DevOps CI/CD pipelines
At Hackolade, we're advocates of Metadata-as-Code.
This strategy has a business purpose to promote a shared understanding of meaning and context for data structures across business users and technical users, through the synchronization and publication of these data structures to business-facing data catalogs.
It also has a technical purpose to ensure that the evolution of data models and their schema artifacts follow the same lifecycle as application code, through their co-location in Git repository and branches.

This strategy gets executed through a combination of our Workgroup Edition features and our Command-Line Interface.
Hackolade Studio Workgroup Edition
With the Workgroup Edition, Hackolade Studio integrates natively with the features, commands, and workflow of Git and the Git platforms: GitHub, GitLab, Bitbucket, and Azure DevOps Repos. This allows for collaboration, versioning, branching, change tracking, peer reviews, conflict resolution, etc.
In the context of Metadata-as-Code, the Workgroup Edition also allows for the co-location of data models and their schema artifacts with the corresponding application code and their respective but coordinated changes in a Git branch. Artifacts also include ALTER scripts, if applicable to the target technology, resulting from model evolutions.
Command-Line Interface
The CLI lets you automatically generate schemas and scripts, or reverse-engineer an instance to infer the schema, or to reconcile environments and detect drifts in indexes or schemas. The CLI also lets you automatically publish documentation to a portal or data dictionary when data models evolve.
With the CLI, you can automate tasks that you would otherwise perform manually in the GUI application. Some Hackolade customers use this capability nightly in a batch process to identify attributes and structures that may have appeared in the data since the last run. During a nightly run of the reverse-engineering function, a much larger dataset can be queried as a basis for document sampling, hence making schema inference more precise. Such capability can be useful in a data governance context to properly document the semantics and publish a thorough data dictionary for end users.
The CLI can also be used in the context of compliance with privacy laws to make sure that the company does not store data that it is not supposed to store. There are many more examples of how to use this functionality.
Another common use case we've seen is to use the CLI to compare the models reverse-engineered from different environments (e.g; dev, test, integration, prod) to ensure their synchronization.
The Hackolade command line can of course be used on a stand alone machine. It can also be easily combined with a git repository for the storage of versioned models and schema artifacts, as well as with Docker containers. Customers have been using this combination either in a push mode, triggered by saving or committing model changes, or in a pull mode, when invoked by a DevOps CI/CD pipeline or a scheduled job. An example of GitHub Actions workflow running the Hackolade Studio CLI is provided here.

The CLI can also be used for end-to-end synchronization of data structures with business-facing data dictionaries:

CLI Orchestration
The orchestration of the commands and arguments is typically scripted, then triggered by an event or a schedule. But the sequence of steps depends on whether development has the upper hand or governance.
Organizations operate in different ways. If development has the upper hand, evolutions tend to happen in a code-first manner, and we see what we've called "retroactive data modeling" or "data modeling after-the-fact."
In other organizations, data modeling happens first, then code changes occur and are implemented in the different environments.
The Hackolade Studio CLI commands can be assembled in the sequence that best fits your exact use case.
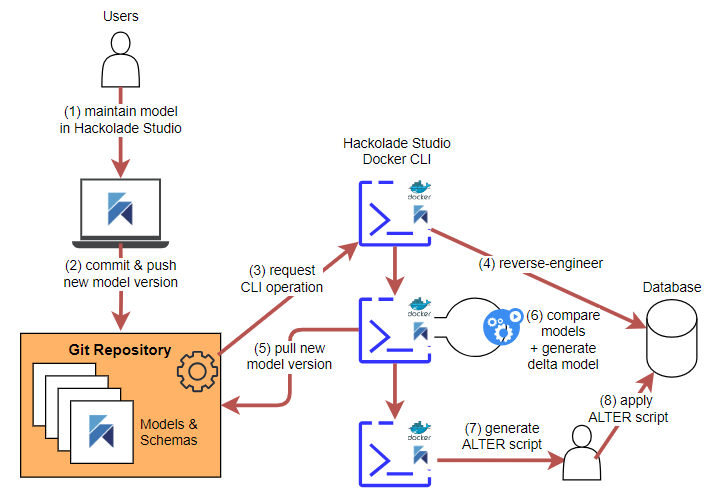
Governance-first use case
In a governance-first approach, a baseline model evolves. When the branch for model changes is merged, the following steps occur:
- Reverse-engineer the database instance using the command “revEng”
- Compare the resulting model with the evolution of the baseline model, using the command “compMod”. This produces a “delta model”
- From the delta model, forward-engineer the ALTER script using the command “forwEng”
- Commit the ALTER script
- Have a DBA review the ALTER script.

You may want to read this architecture article to see the details of this diagram:
Code-first use case
In a code-first approach, the structure in the production instance evolves. Every night, a scheduled process goes through the following steps:
- Reverse-engineer the database instance using the command “revEng”
- Compare the resulting model with the baseline model, using the command “compMod”. This produces a “delta model” and optionally a “merged model”
- We suggest here a manual step to review the model comparison and identify whether all changes in production are legitimate. Maybe adjustments are necessary to the code, data needs migration, etc… Produce a new merged model if necessary.
- Commit the merged model which becomes the new baseline model

Developing and fine-tuning the CLI commands
Many other combinations are possible, and the examples above should inspire the approach fitting your specific use case. You may want to watch a playlist of short videos on YouTube.
Creating the orchestration of the CLI commands with the proper arguments can be tricky so we suggest the following tips and best practices:
- Start by executing with the GUI the different steps of the full workflows and ensure that the you can produce the expected results from the GUI application;
- Familiarize yourself with the CLI, and start small before building up in complexity. For example, start by displaying the arguments for your command before writing a huge number of complex arguments. Also, folder paths quickly add complexity. Don't make your life too complicated at first, with complex locations or path variables without validating first that the command works well locally.
- Divide and conquer: develop the command arguments and fine-tune each command, one at a time. And only assemble them in a script when each command has been fully validated.
- When doing model comparisons, beware of which model is model1 and which is model2, as it has an influence on the direction of the ALTER scripts (i.e. what object gets added or deleted), as well as on conflict resolution. We strongly suggest experimenting with the Compare & Merge screen to visually understand the behavior.
- Test, test, and re-test... And validate that the output is as expected in various circumstances.