
Glue Data Catalog
AWS Glue is a fully managed extract, transform, and load (ETL). AWS Glue discovers data and stores the associated metadata (e.g. table definition and schema) in the AWS Glue Data Catalog. Once cataloged, data is immediately searchable, queryable, and available for ETL. The AWS Glue Data Catalog is a fully managed, Apache Hive 2.x metadata repository for all data assets, regardless of where they are located. The Data Catalog contains table definitions, job definitions, and other control information to help manage a AWS Glue environment.
To perform data modeling for the AWS Glue Data Catalog with Hackolade, you must first download the Glue plugin. The plugin is based on the Hive plugin, but specifically tuned to interact with AWS Glue using the AWS CLI commands.
Hackolade was specially adapted to support the data modeling of the the AWS Glue Data Catalog, including Glue metadata and Hive primitive and complex datatypes, and producing both AWS CLI commands and HQL Create Table syntax. The application closely follows the Hive terminology and storage structure.
The data model in the picture below results from the modeling of an application described in this AWS Blue tutorial.

Tables
Tables in in the Glue Data Catalog contain references to data that is used as sources and targets of extract, transform, and load (ETL) jobs in AWS Glue.
Standard tables
The table properties are based on Hive 2.x metadata structure.


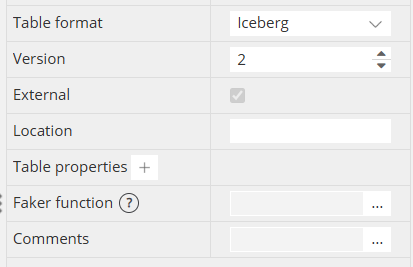
Iceberg tables
AWS announced S3 Tables, which brings native support for Apache Iceberg to S3. AWS Glue 3.0 and later supports the Apache Iceberg framework for data lakes. Iceberg provides a high-performance table format that works just like a SQL table. This isn’t a separate service that sits on top of S3. Rather AWS has added a new type of bucket to the S3 service itself: a table bucket. Table buckets come with a host of new APIs. It’s the stuff you’d expect for working with Iceberg tables. To name a few: CreateNamespace, CreateTable, ListTables, RenameTable, PutTableMaintenanceConfiguration.
AWS Glue can be used to perform read and write operations on Iceberg tables in Amazon S3, or work with Iceberg tables using the AWS Glue Data Catalog. AWS Glue Data Catalog feature1 that automatically mirrors the catalogs from the S3 table buckets in your account like this diagram provided from this article, along with additional valuable insights:
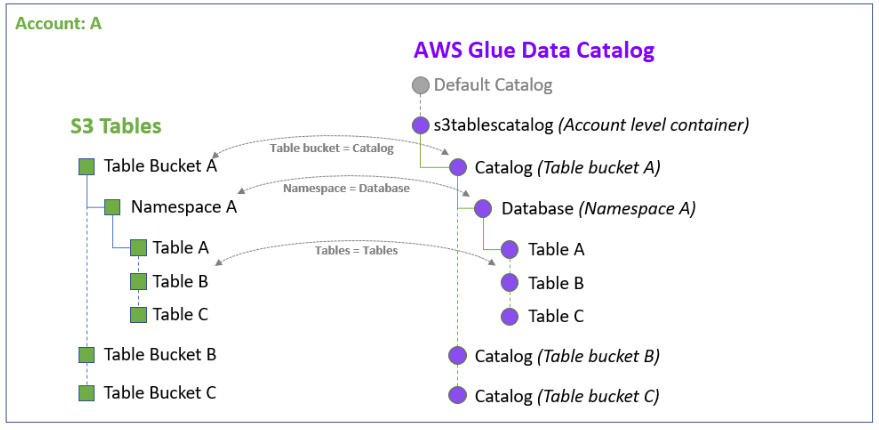
Hackolade Studio supports Iceberg tables in AWS Glue Data Catalog, including the ability to maintain the relevant properties, plus forward- and reverse-engineering.
Partition keys, buckets
The Glue Data Catalog organizes tables into partitions for grouping same type of data together based on a column or partition key. Each table can have one or more partition keys to identify a particular partition. Using partition we can also make it faster to do queries on slices of the data. Tables or partitions are subdivided into buckets based on the hash function of a column in the table to give extra structure to the data that may be used for more efficient queries.
Data types
The Glue Data Catalog supports different data types to be used in table columns. The data types supported can be broadly classified in Primitive and Complex data types.
Hackolade was specially adapted to support the data types and attributes behavior of the AWS Glue Data Catalog, including arrays, maps and structs.

Forward-Engineering
Hackolade dynamically generates both the AWS CLI command and the HQL script to create tables, columns and their data types, and indexes for the structure created with the application. The AWS CLI command can be applied directly to the instance, provided that the user profile is granted sufficient rights.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.

As many people store JSON within text columns, Hackolade allows for the schema design of those documents. That JSON structure is not forward-engineered, but is useful for developers, analysts and designers.
Reverse-Engineering
The connection is established using a connection using AWS IAM credentials:

or through the credentials file of the AWSCLI.
The Hackolade process for reverse-engineering of Glue Data Catalog databases includes the execution of AWS CLI glue statements to discover tables, columns and their types. If JSON is detected in text columns, Hackolade performs statistical sampling of records followed by probabilistic inference of the JSON document schema.
For more information on the AWS Glue Data Catalog in general, please consult the AWS website.