
Couchbase with scopes and collections
Couchbase is a distributed, JSON document database. With their version 7, Couchbase introduced a new storage model with scopes and collections, allowing documents to be categorized and organized. Previously within a bucket, you mostly stored all kinds of different document types within the same physical bucket.
Couchbase Server is an open-source, distributed multi-model NoSQL document-oriented database software package that is optimized for interactive applications. It natively manipulates data in key-value form or in JSON documents.
To perform data modeling for Couchbase with Scopes & Collections with Hackolade Studio, you must first download the CouchbaseV7plus plugin.
Hackolade Studio was specially built to support the data modeling of Couchbase v7+ scopes and collections, The application closely follows the terminology of the database.
The data model in the picture below results from the reverse-engineering of the sample travel application described here.

In older versions of Couchbase (up to v6.6) within a cluster, data was organized in this hierarchy:
- Bucket
- Document type
- Document
In Couchbase 7.0, two new organizational layers have been inserted, Scope and Collection, thus the hierarchy now looks like the following (documents exist only in Collections):
- Bucket
- Scope
- Collection
- Document
To provide an easy upgrade path coming from earlier versions of Couchbase, every created bucket is automatically given a default scope, and within it, a default collection. Each is named _default.
You can find more details in this Couchbase page.
Buckets
If you worked with Couchbase versions up to v6.6, the way documents are organized within buckets has evolved drastically!
If you think in database terms, a Couchbase bucket is still analogous to a database: it’s the data store where you’re going to store and retrieve related information. There is still a limit of the number of buckets allowed per cluster, but the limit has been raised to 30.
| Concept | pre-v7 | v7+ (old model) | v7+ (new model) |
|---|---|---|---|
| Container | bucket | _default bucket | scope |
| Entity | document kind | document kind | collection |
| Attribute | field | field | field |
Scopes and collections contained in a bucket are just logical containers within that bucket. Developers may use them to isolate schemas and organize data. Database administrators might use them to isolate tenants, and control access or replication.
Read more about buckets vs collections.
Scopes
Scopes are the level of organization below a bucket. Scopes contain collections and collections contain documents. There are different ways to use scopes, depending on what the Couchbase cluster is being used for. If it is supporting many different internal applications for a company, each application should have a scope of its own. If the cluster is being used to serve many client organizations, each running its own copy of an application, each copy should have a scope of its own. Similarly, if a cluster is being used by dev groups, perhaps for testing, the unit of allocation should be a scope. In each case, the owner can then create whatever collections they want under the scope they are assigned.
A scope acts as a parent to collections. This is is a container, similar to a schema or namespace in other database technologies..
Collections
Collections are the lowest level of document organization, and directly contain documents. They are useful because they let you group documents more precisely than was possible before. Rather than dumping all different types of documents (products, orders, customers) into a single bucket and distinguishing them by a type field, you can instead create a collection for each type. And when you query, you can query against the collection, not just the whole bucket. You will also eventually be able to control access at the collection level.
Documents
A document refers to an entry in the database (other databases may refer to the same concept as a row). A document has an ID (primary key in other databases), which is unique to the document and by which it can be located. The document also has a value which contains the actual application data.
Documents are stored as JSON on the server. Because JSON is a structured format, it can be subsequently searched and queried.
Keys
A modeling characteristic distinguishes Couchbase from some other NoSQL document databases: the unique key of each document is stored 'outside' the JSON document itself. Couchbase was originally a key-value store. With version 2.0, Couchbase bridged the gap to being a multi-model database supporting JSON documents. In essence, the key part remains, and the value part can also be a JSON document. The fundamental difference is that a pure key-value database doesn't understand what's stored in the value, while a document database understands the format in which documents are stored and can therefore provide richer functionality for developers, such as access to documents through queries.
Document IDs can be assigned by the software application. A valid document ID must:
- Conform to UTF-8 encoding
- Be no longer than 250 bytes
Users are free to choose any ID for their document, so long as they conform to the above restrictions. This feature can be leveraged to define natural keys where possible, so they can be human-readable, deterministic, and semantic.
If a document is committed without an ID, one will be automatically generated as a UUID by the database. See more details here.
Flexible key design
Starting with v7.5.0, you may now define the structure of your primary key with a flexible design using existing constants, patterns, separators, and existing fields. This capability allows you to implement strategies illustrated on this page.
In a basic use case, you could have a simple document key made of single unique identifier. Unique identifiers could be natural keys, for example an email address. The advantage is that their contextual meaning is well understood by humans and as a result are predictable. But they are less flexible in the case for example when the value must change for the same document, for example if a user changes email address. Unique identifiers can also be surrogate keys, where a meaningless unique identifier like a UUID is used as the key. It may be unpredictable and harder to read or type, but it is more scalable and flexible.
With this flexible key design, it is now possible to structure a composite key (a.k.a compound key) and assemble multiple segments. For example, given this document model:
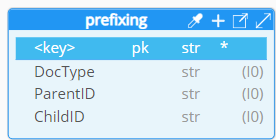
and the defined PK structure:
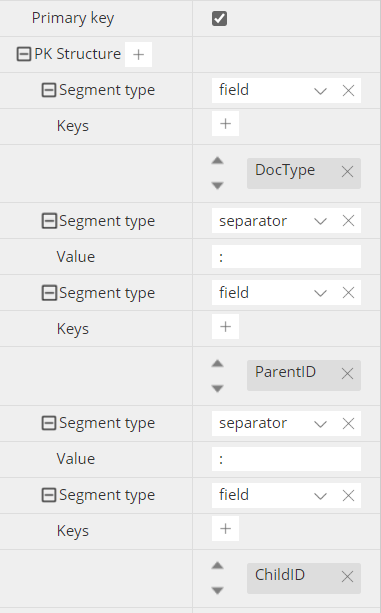
an example of key could be this:

You may define PK Structure using 4 types of segments: constant, field, separator, and regex pattern. There is no theoretical limit to the number of segments, but the total length of the key cannot exceed 250 bytes. If you use a numeric field for a segment, it should ideally be an integer, and it will be converted to a string (as the key can only be of string data type.
Typical separators for Couchbase are column (:), double column (::) or hash (#). Separators are not mandatory, but they are strongly recommended, at least between fields, as they facilitate parsing, and inference during reverse-engineering.
Attributes data types
Couchbase attributes support standard JSON data types, including lists and sets (arrays), and maps (objects). The Hackolade menu items, contextual menus, toolbar icon tooltips, and documentation are adapted to Couchbase's terminology and feature set. The following words are reserved.
Hackolade was specially adapted to support the data types and attributes behavior of Couchbase.

Indexes
An index is a data-structure that provides quick and efficient means to query and access data, that would otherwise require scanning a lot more documents. Couchbase Server provides different types of indexes, as documented here. .
Hackolade supports the creation, documentation, forward- and reverse-engineering of:
- Primary: Provided by the Index Service, this is based on the unique key of every item in a specified bucket. Every primary index is maintained asynchronously. A primary index is intended to be used for simple queries, which have no filters or predicates.
- Secondary: Provided by the Index Service, this is based on an attribute within a document. The value associated with the attribute can be of any type: scalar, object, or array. A Secondary Index is frequently referred to as a Global Secondary Index, or GSI. This is the kind of index used most frequently in Couchbase Server, for queries performed with the N1QL query-language.
Views (TBA)
Views and indexes support querying data in Couchbase Server. Querying of Couchbase data is accomplished via the following:
- MapReduce views accessed via the View API.
- Spatial views accessed via the Spatial View API.
- N1QL queries with Global Secondary Indexes (GSI) and MapReduce views.
There are a number of differences between views and GSIs. At a high level, GSIs are built for N1QL queries, which are great for supporting interactive applications that require fast response times. Views, on the other hand, provide sophisticated user defined functions to provide great flexibility in indexing. Views can support complex interactive reporting queries with a pre-calculated result.
More information on views can be found here.
Reverse-Engineering
The connection is established using a connection string including (IP) address and port (typically 8091) if run locally, or from the DBaaS Capella Cloud offering of Couchbase, and authentication using username/password if applicable.
For more information on Couchbase in general, please consult the website.
Forward-Engineering
For those developing Node.js applications on top of a Couchbase database, you may want to leverage the object document mapper (ODM) Ottoman that allows you build what your object model would look like, then auto-generate all the boilerplate logic that goes with it. Hackolade dynamically generates the Ottoman script based on model attributes and constraints. More information on Ottoman here and here.
We provide a sort of "forward-engineering by example", with an automatic JSON data sample generation. The script also includes the creation of indexes, and it can be applied to the database instance, provided that appropriate credentials are granted to the user. If the specified bucket does not exist, we attempt to create it.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.
